 |
given a set S of line segments, find all pairs in the set that intersect.
Note: when all segments meet at a point,
the answer size in this formulation is Omega(n2).
project segments to x-axis
find all pairs of overlapping projection intervals.
check if real intersections
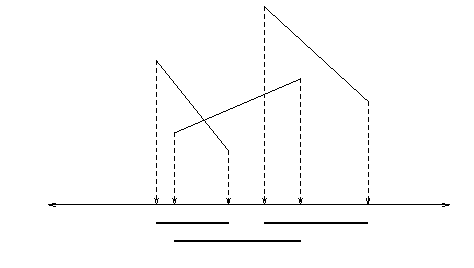
walk along real line,requires sorting endpoints, considering each one by one.
keep track of set C of intervals containing current point
this set changes only at endpoints
at the left endpoint of interval J, report meetings of J with C and add to C.
at the right endpoint, delete J from C.
All of these are Omega(n2) worst case, even when A=0.
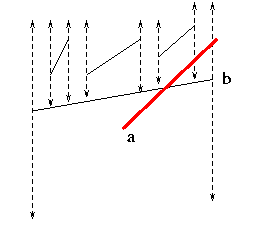
sweep a vertical line through the segments
maintain set of segments that the line meets,
just like projection method
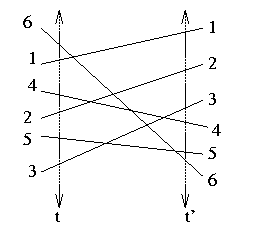
That is, view the x-coordinate as "time": something true for the vertical line x=t will be said to be true at time t.
The y-coordinate of a segment at time t is the the y-coordinate of the intersection of the segment with the line x=t.
A segment is active for sweep lines that meet it, and so segment p--q is active from time px to time qx.
The sweep algorithm keeps track of the order of the active segments along the sweep line, in an ordered list: that is, segments at each time t are sorted by y-coordinate.
Call that ordered list the status.
|
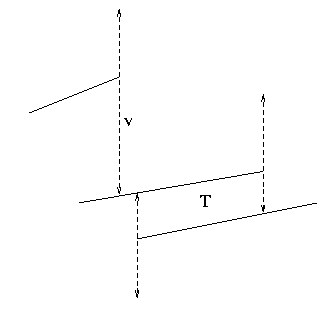
The status changes only when:
a segment becomes active,So the algorithm keeps a schedule of these events, and does operations on the status to account for changes when the events occur.
a segment becomes inactive, or
when two segments meet.
When a segment becomes active, it is inserted into the status.
When a segment becomes inactive, it is deleted from the status.
When two segments meet, their order in the status reverses.
What does it mean to "schedule" an event?
For the projection algorithm, the endpoints could be sorted,
but intersection events are unknown beforehand.
SO, use a heap of events, so that the "next" event,
at smallest next time, can be found.
Where does a segment go in the status?
if the segment is added at time t,
compare its y-coordinate at time t with the
y-coordinates of the active segments at time t.
Plainly, only segments that are active at the same time can meet; but even more is true:
Key observation:
|
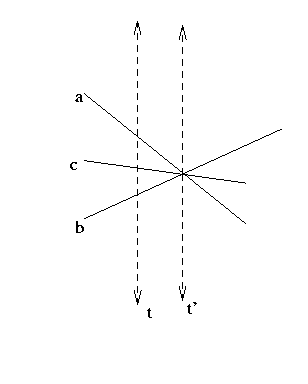
At any time t,
suppose the next upcoming event, at time t',
is an intersection of segments a and b;
then all segments between a and b along the sweep line
also meet a and b at time t'.
This implies: it's enough to schedule intersection events involving segments that are adjacent along the sweep line. Proof: c is active at time t |
|
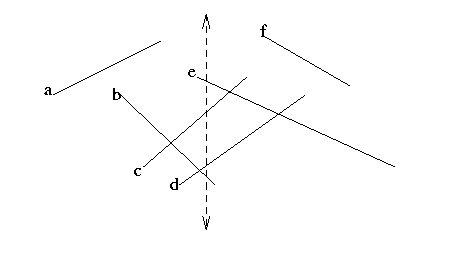
When do segments become adjacent along the sweep line?
...at an insertion, deletion, or intersection event.Schedule any such events found.
when inserting segment a: check if a meets its neighbors in status
when deleting segment a: check if the neighbors of a above and below meet.
at intersection event, where a was above b:
check if a meets b's old neighbor below, and
b meets a's old neighbor above.
Keeping track of adjacencies. need to:
insert and delete entries in status;
find place of new segment in status
a dynamic ordered list is needed -->use a balanced binary tree, or skip list
There are 2n+A events, so O(n+A)log n time needed.
The status has no more than n segments; for suitable random data, O(sqrt n) on average.
What about the heap?
2n endpoint events scheduled;
At most A intersection events scheduled, so O(n+A) space.
Even better is possible by changing the algorithm:
As described, an intersection event is scheduled when
two segments become adjacent in the status;
they may then become nonadjacent.
However, it suffices to have events scheduled
only for currently adjacent segments.
-->when two segments become nonadjacent,
remove their intersection event.
could just special-case it.What about multiple segments meeting at the same point?
or: use lexicographic tie-breaking, so
if events (x,y) and (x,y') have y<=y', consider (x,y) first.
equivalent to rotating the coordinate system
an infinitesimal amount. a vertical segment's events occur from bottom endpoint,
through intersections with segment on the status,
to its top endpoint.
multiple start endpoints: use order of segments a tiny moment later,
that is, look at rotation order about common endpoint
multiple segments meeting at an intersection: delete from status, and reinsert
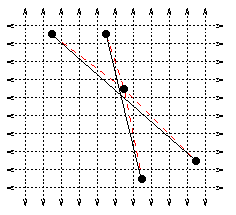 |
all segments initially have endpoints on an integer grid; when two segments meet, the intersection point is "snapped" to the nearest gridpoint this results in polygonal lines approximating the input segments segments passing near gridpoints with intersections are also snapped This introduces no new intersections |
 |
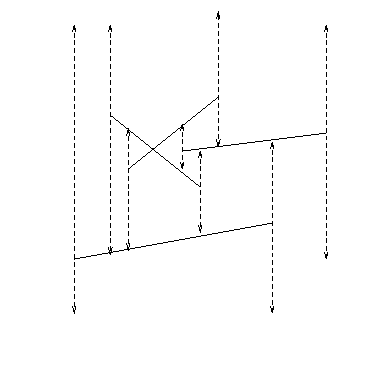
between time t and t', suppose no endpoint events occur then two segments are in different order at t than at t' iff they cross in between. Adjacent segments in status can be checked for ordering So processing is like sorting status into order at time t', using swaps of adjacent segments Any order of swapping will do. |
true for single edge or node;
maintained under adding an edge
for each edge, can find its endpoints
for each face, can find its edges in order
for each vertex, can find its incident edges in order
put a new vertex in each face,
connect with vertices around face
represent triangulation so that
each triangle knows its vertices and neighboring triangles
slightly faster asymptoticallyThe algorithm builds the
leads to
a planar point location data structure,
a near-optimum simple polygon triangulation algorithm
a divide-and-conquer approach
Trapezoidal diagram of the segments:
...the subdivision induced by the segments, together with
visibility edges, for endpoints and crossing points:
an edge from the point to the point on theeach face is a trapezoid (in a generalized, possibly-infinity sense)
nearest segment directly above (or nearest below)
the edge could be a ray to infinity, if nothing hit
such visibilities are easily found during sweep
The algorithm, in outline:
order the segments by a random permutation p1...pn
for i=1..n,
maintain TD(Ri), where Ri=={p1..pi}
To compute TD(Ri+1) from TD(Ri):
must determine effect of segment pi+1:
find trapezoids meeting pi+1
split some traps with new visibility edges
merge some traps: some visibility edges are blocked by pi+1
Given that the trapezoid T containing the left endpoint of pi+1 is known,
the remaining trapezoids meeting pi+1
can be found by traversing the diagram along pi+1
we will show bounds on the work for the traversal
The work to update is linear in the number of traps meeting pi+1
So, somewhat like the randomized incremental algorithm for 2d planar convex hull, there are basically three problems:
To make a random permutation, make an array Z with Z[i]=i for i=1..n, and
for i = n downto 1 pick a random number j with j <= i; swap Z[i] and Z[j]
== sumx,y x Prob(X=x,Y=y) + sumx,y y Prob{X=x, Y=y}That is, E(X+Y) = EX + EY
== sumx x sumy Prob(X=x, Y=y) + ...
== sumx x Prob(X=x) + ...
== EX + EY
Back to trapezoidal diagrams:
For a given point p,
the work to update the trapezoid containing p is O(1), when that trapezoid changes.
How many times does a change of containing trapezoid occur?
We'll consider the probability that the containing trapezoid changes when pi
is added.
For this analysis, we need this
Observation: Any trapezoid T in TD(Ri) "determined" by no more than 4 segments: that is, T is in TD(S') for some S' subset S of size 4.
Call the segments in S' incident to T.
Moreover,
if T is in TD(S'), and
S' is a subset of Ri, and
no segment of S meeting T is in Ri,
then T is in TD(Ri).
If a change occurs for p when pi is added,
then pi is incident to the new containing trapezoid.
Put another way, let T be the trapezoid of TD(Ri) containing p, determined by some set S' of 4 segments of Ri.
Then a change occurs at step i iff pi is a member of S'.
For a given set Ri,
pi is a random element of Ri, and so
the probability that this occurs is 4/i.
Let Ji be a random variable,
Ji = 1 if the trapezoid containing p changes at step i,
Ji = 0 otherwise.
Then the expected work for p is the expected value of
sumi Ji = sumi EJi (by linearity of expectation)
=sumi 1/i = O(log n).
Lemma 1. The expected work for search is O(n log n).
Before considering the update cost, we need to look at:
The number of segment endpoints is 2i
Let Ai be the number of intersection points of Ri
The number of endpoints of visibility edges is <=2(2i+Ai)
So v<=3(2i+Ai)
{n-2 choose i-2} / {n choose i} == {i choose 2} / {n choose 2}, or about i2/n2
Let Jp be a random variable that is
1 when p is an intersection point of RiThen the expected value EJp = i(i-1)/n(n-1),
0 otherwise
Lemma 2: The expected number of vertices of TD(Ri) is O(i+Ai2/n2).
(For convex hulls, the analogous problem was easy: two edges created per step.)
If trapezoid T is created when pi is added, then pi is incident to T.
Now consider T in TD(Ri);
what is the probability that T was created when pi was added?
That is, what is the probability that pi is a member of the S' for T?
Ri has i segments, and at most 4 of them are in S', so this probability
is <=4/i.
The expected size (number of trapezoids) of TD(Ri) is O(i+Ai2/n2), from Lemma 2, and this is independent of the choice of pi, so
Lemma 3. The expected number of trapezoids created over the course of the algorithm is sumi O(i+Ai2/n2)/i = O(n+A).
|
It may be necessary to visit trapezoids that do not meet a new segment,
in order to find those that do.
This additional work occurs when the boundary segment of a trapezoid is broken up by visibility edges from above.
|
|
|
To bound the work of this kind, consider a configuration consisting
of a trapezoid with a "tail": a trapezoid together with
a visibility edge dividing its boundary.
Such a tail gives a subdivision of the boundary of the trapezoid. Since the TD is planar, the total number of such tails is O(n+A). This trap+tail configuration is determined by a set S' of at most 6 segments, just as a trapezoid is determined by at most 4 segments. |
|
When a segment traverses the graph, work is done for such a configuration if the segment meets the trapezoid, after which the configuration is gone.
So the total work for traversals is proportional to the total number of such configurations, which is O(n+A); the argument is similar as for updates, but with "6" replacing "4".
Putting these facts together, we get:
Theorem. The randomized incremental algorithm needs O(A + n log n) time to find the trapezoidal diagram of n segments with A intersecting pairs.