Slides for SLMath Summer School
The Mathematics of Big Data: Sketching and (Multi-) Linear Algebra
(Slides on matrix sketching)
Ken Clarkson
IBM Research
In the html version, navigate with arrow keys, or arrowset in lower right of slides;
major sections navigate "left and right", within sections "up and down"
Introduction, Algorithmic Motivation
\( \newcommand\norm[1]{|| #1 ||} \newcommand{\norme}[1]{{\myvertiii{#1}}} \newcommand{\myvertiii}[1]{{\left\vert\kern-0.2ex\left\vert\kern-0.2ex\left\vert #1 \right\vert\kern-0.2ex\right\vert\kern-0.2ex\right\vert}} \newcommand\E{\mathrm{E}} \DeclareMathOperator\Var{Var} \DeclareMathOperator\Cov{Cov} \DeclareMathOperator\stdev{Stdev} \DeclareMathOperator\cgf{CGF} \DeclareMathOperator\Prob{Pr} \DeclareMathOperator\subg{subG} \DeclareMathOperator\dist{dist} \DeclareMathOperator\KJL{K_{JL}} \newcommand\nnz[1]{{\textrm{nnz}(#1)}} \DeclareMathOperator\Dist{\mathbf{Dist}} \DeclareMathOperator\diam{diam} \DeclareMathOperator\reals{{\mathrm{I\!R}}} \DeclareMathOperator\R{{\mathrm{I\!R}}} \DeclareMathOperator\poly{poly} \DeclareMathOperator\polylog{polylog} \DeclareMathOperator\rank{rank} \DeclareMathOperator\im{im} \DeclareMathOperator\range{im} \DeclareMathOperator\rowspan{rowspan} \DeclareMathOperator\colbasis{colbasis} \DeclareMathOperator\trace{tr} \DeclareMathOperator\diag{diag} \DeclareMathOperator\argmin{argmin} \DeclareMathOperator\Err{{\mathtt{NE}}} \newcommand\eps{{\epsilon}} \DeclareMathOperator\argmax{argmax} \DeclareMathOperator\cost{cost} \DeclareMathOperator\OPT{{\mathtt{OPT}}} \DeclareMathOperator\sr{sr} \DeclareMathOperator\sd{{\mathtt{sd}}} \newcommand\cN{{\mathcal N}} \newcommand\cR{{\mathcal R}} \newcommand\cP{{\mathcal P}} \newcommand\cS{{\mathcal S}} \newcommand\cL{{\mathcal L}} \newcommand\cD{{\mathcal D}} \newcommand\cM{{\mathcal M}} \newcommand\cE{{\mathcal E}} \newcommand\cC{{\mathcal C}} \newcommand\tO{{\tilde O}} \newcommand\hphi{{\hat\phi}} \newcommand\symd[1]{#1^\top#1 - \Iden} \newcommand\twomat[2]{\left[\begin{smallmatrix} #1 \\ #2 \end{smallmatrix} \right] } \newcommand\maybemathbf[1]{\mathbf{#1}} \DeclareMathOperator\bfone{{\mathbf{1}}} \newcommand\mZero{\maybemathbf{0}} \newcommand\Iden{\maybemathbf{I}} \newcommand\mSig{\maybemathbf{\Sigma}} \newcommand\mLam{\maybemathbf{\Lambda}} \newcommand\mPi{\maybemathbf{\Pi}} \newcommand\mA{\maybemathbf{A}} \newcommand\mB{\maybemathbf{B}} \newcommand\mC{\maybemathbf{C}} \newcommand\mD{\maybemathbf{D}} \newcommand\mE{\maybemathbf{E}} \newcommand\mG{\maybemathbf{G}} \newcommand\mH{\maybemathbf{H}} \newcommand\mM{\maybemathbf{M}} \newcommand\mN{\maybemathbf{N}} \newcommand\mP{\maybemathbf{P}} \newcommand\mQ{\maybemathbf{Q}} \newcommand\mR{\maybemathbf{R}} \newcommand\mS{\maybemathbf{S}} \newcommand\mT{\maybemathbf{T}} \newcommand\mU{\maybemathbf{U}} \newcommand\mV{\maybemathbf{V}} \newcommand\mW{\maybemathbf{W}} \newcommand\mX{\maybemathbf{X}} \newcommand\mY{\maybemathbf{Y}} \newcommand\mZ{\maybemathbf{Z}} \newcommand\va{\maybemathbf{a}} \newcommand\vb{\maybemathbf{b}} \newcommand\vd{\maybemathbf{d}} \newcommand\ve{\maybemathbf{e}} \newcommand\vg{\maybemathbf{g}} \newcommand\vh{\maybemathbf{h}} \newcommand\vm{\maybemathbf{m}} \newcommand\vp{\maybemathbf{p}} \newcommand\vr{\maybemathbf{r}} \newcommand\vs{\maybemathbf{s}} \newcommand\vw{\maybemathbf{w}} \newcommand\vx{\maybemathbf{x}} \newcommand\vy{\maybemathbf{y}} \newcommand\vz{\maybemathbf{z}} \newcommand\vtau{\boldsymbol{\tau}} \newcommand\tmA{\tilde{\maybemathbf{A}}} \newcommand\tmW{\tilde{\maybemathbf{W}}} \newcommand\tmZ{\tilde{\maybemathbf{Z}}} \newcommand\tmY{\tilde{\maybemathbf{Y}}} \newcommand\tmX{\tilde{\maybemathbf{X}}} \newcommand\tmV{\tilde{\maybemathbf{V}}} \newcommand\tmH{\tilde{\maybemathbf{H}}} \newcommand\bmP{\bar {\maybemathbf{P}}} \newcommand\tvx{\tilde{\maybemathbf{x}}} \newcommand\tva{\tilde{\maybemathbf{a}}} \newcommand\tvb{\tilde{\maybemathbf{b}}} \newcommand\hmY{\maybemathbf{\hat Y}} \newcommand\hmS{\maybemathbf{\hat S}} \newcommand\hmR{\maybemathbf{\hat R}} \newcommand\hmA{\maybemathbf{\hat A}} \newcommand\hvb{\hat {\maybemathbf{b}}} \)Outline
- Randomized Estimation
- Algorithms for
- Linear Algebra
Outline
- Linear Algebra
- Randomized Estimation
- Algorithms
Regression



`\vb\in\R^n` is a column vector
`\mA_{i*}` is row `i` of `\mA`
`(\mA_{i*}, b_i)` for `i \in [n]` is an input set of points
find $$\min_{\vx\in\R^d} \sum_i M(\mA_{i*} \vx - b_i)$$ Generically, an `M`-estimator.
`\mA\vx - \vb` is the residual


- `M(z)=z^2`, least-squares regression [G95][L05]
- Minimize the Euclidean norm `\norm{\mA\vx - \vb}` of the residual
- `M(z)=|z|^p` for some `p\ge 1`, `\ell_p` regression
`\qquad` e.g., `p=1`, a.k.a. least absolute deviations
Least squares is still important
Besides immediate data science applications,least squares can be in the "inner loop" for:
- Interior point methods for linear programming
- Multiple-response least-squares with manifold constraints
- Generalized linear models
- Training neural networks
- Tensor decomposition
(Some) notation and conventions
In one place, in case I forget to say
- Matrices, e.g. `\mA`, are denoted with bold upper case
- `\mA_{i*}` is row `i` of matrix `\mA`
- `\mA_{*j}` is column `j` of `\mA`
- `a_{ij}` (or sometimes `A_{ij}`) are entries of matrix `\mA`
- Vectors, e.g. `\vx`, are bold lower case, and are columns unless otherwise indicated
- Entries of matrices and vectors are real numbers
- `\nnz{\mA}` is the number of nonzero entries of `\mA`: often, the input size
- `\norm{\vx}` is the Euclidean norm
- `\norm{\mA}_2` is the spectral norm (sometimes, dropping the subscript 2)
- `\mA^\top\in\R^{d\times n}` is the transpose, with entries `A^\top_{ji} = A_{ij}` for `i\in [n], j\in [d]`
- `\mA^+\in\R^{d\times n}` is the Moore-Penrose pseudo-inverse, with `\mA\mA^+\mA = \mA`, `\mA^+\mA\mA^+=\mA^+`
- `\Iden_d\in\R^{d\times d}` is the identity matrix, with entries `I_{ii}=1`, and 0 otherwise;,
- `\ve_i\in\R^n`, for `i \in[n]` are the natural basis (standard basis) vectors
`\qquad` where `\ve_i = \Iden_{i*}`, with `i`'th coordinate 1, and 0 otherwise. - `\im(\mA)\equiv \{\mA\vx \mid \vx\in\R^d\}` is the image (a.k.a. column span, range) of `\mA\in\R^{n\times d}`
- `\rank(\mA) \equiv \dim(\im(\mA))`
- `\trace(\mA) = \sum_i a_{ii}`, the sum of the diagonal entries
- `\diag(\vd)`, for `\vd\in\R^n`, is the diagonal matrix `\mD\in\R^{n\times n}` with `D_{ii}=d_i`
- `[n]\equiv\{1,2,\ldots,n\}`, for positive integer `n`
- `a\wedge b` denotes `\min\{a,b\}`, for `a,b\in\R`
- `g(n)=O(f(n))` as `n\rightarrow\infty` denotes `\exists C,n_0` with `n\ge n_0\implies g(n)\le Cf(n)`; `\tO(f)` denotes `f\log^{O(1)}f`
- `x=(1\pm \eps)y` means, for real `x,y` and `\eps\ge 0`, that `|x-y| \le \eps |y|`
- `x\approx_\eps y` means `x=(1\pm\eps)y`
- `\poly(k)` means `k^{O(1)}`
Low-rank approximation: fitting data

Given: points `\mA_{*j}` as columns of matrix `\mA`
Fit: a `k`-dimensional subspace `L_k^*` minimizing
$$\cost(\mA,L) \equiv \sum_{j\in [d]} \dist(\mA_{*j},L)^2$$
`L=\im(\mY)=\{\mY\vx\mid\vx\in\R^k\}` for some `\mY\in\R^{n\times k}`
So `\mA_{*j}\approx\mY\vx`, for some `\vx\in\R^k`,
that is, a linear combination of the columns of `\mY`.
Making this column `\mX_{*j}` of matrix `\mX\in\R^{k\times d}`,
and the distance Euclidean,
we are
solving, for all `j\in[d]`, the least-squares problem
`\min_{\mX_{*j}\in\R^k} \norm{\mA_{*j}-\mY\mX_{*j}}^2`. Putting these together:
For fixed `\mX`, least-squares for each row of `\mA` and corresponding row of `\mY`
Randomized approximation
- These problems involve norms of vectors and/or matrices:
- `\norm{\mA\vx-\vb}`, the norm of the least-squares residual
- `\norm{\mA-\mY\mX}_F`, the approximation error for `\mY\mX`
- Squared norms are sums `\norm{\vw}^2=\sum_{i\in[n]} w_i^2`
- To estimate sums, we can use randomization
Linearity of expectation, Markov's inequality, and union bounds
`\E[\mA\vx]_i = \E[\mA_{i*}\vx] = \sum_{j\in[d]} a_{ij}\E[x_j] = \mA_{i*}\E[\vx]`; that is, `\E[\mA\vx]=\mA\E[\vx]`.
`\begin{align*} \Prob\{\cup_i E_i\} & = \Prob\{\textstyle\sum\nolimits_i X_i \gt 0\} \\ & \le \E[\textstyle\sum\nolimits_i X_i] \qquad \mathrm{\ Markov\ inequality}, t=1 \\ & = \textstyle\sum\nolimits_i \E[X_i] \qquad \mathrm{\ linearity\ of\ } \E \\ & = \textstyle\sum\nolimits_i \Prob\{E_i\} \end{align*}`.
Product and norm estimation using randomization
entries `s_i` with `\E[s_i^2]=1` for `i\in [n]` and `\E[s_is_j]=0` for `i,j\in [n], i\ne j`
then for `\vx,\vy\in\R^n`, `\E[(\vs\cdot\vx)(\vs\cdot\vy)] = \E[(\vs^\top \vx)(\vs^\top \vy)] = \E[\vx^\top\vs\vs^\top\vy] = \vx^\top\vy`.
In particular, `\E[(\vs^\top\vy)^2] = \E[\vy^\top\vs\vs^\top\vy] = \vy^\top\vy = \norm{\vy}^2`.
So `\E[\vx^\top\vs\vs^\top\vy] = \vx^\top\E[\vs\vs^\top]\vy = \vx^\top\Iden_n\vy= \vx^\top\vy.`
`s_i \sim \cN(0,1)` independent
Since `\E[s_i]=0`, `\E[s_i^2] = \Var(s_i)=1`.
For `i\ne j`, independence implies `\E[s_is_j]=\E[s_i]\E[s_j]=0`.
Pick `k\in[n]` with prob. `\frac1n`, `s_k\gets \sqrt{n}`, `0` o.w.
`\E[s_i^2] = \frac{1}{n}\sqrt{n}^2 + (1-\frac{1}{n})0 = 1`.
Also `s_i\ne 0 \implies s_j=0` for `i\ne j`,
`\quad` so `s_is_j=0`.
Since `\vs^\top(\mA\vx - \vb) = (\vs^\top\mA)\vx - (\vs^ \top\vb),`
this is faster for multiple `\vx`,
(even for sketching)
if `\vs^\top\mA` and `\vs^\top\vb` are pre-computed.
Accuracy: not so good
Algorithms
With repetition and better distributions, randomization can be much more accurate.
Repetition means:independent rows, each row `\frac{1}{\sqrt{m}}` times an AMM vector,
then $$\E[\mS^\top \mS] = \E[\sum_{i\in[m]} [\mS_{i*}]^\top \mS_{i*}] = \sum_{i\in[m]} \E[[\mS_{i*}]^\top \mS_{i*}] = \sum_{i\in [m]} \frac{1}{m}\Iden = \Iden,$$ so for `\vx,\vy\in\R^n`, `\E[(\mS\vx)\cdot (\mS\vy)] = \E[\vx^\top\mS^\top \mS\vy] = \vx^\top\E[\mS^\top \mS]\vy = \vx^\top\vy`.
In particular, `\E[\norm{\mS\vy}^2] = \norm{\vy}^2`.
Many things can be done with such sketching matrices: there is a large cross-product $$\text{Randomized techniques} \times \text{Matrix problem} \times \left\{\begin{matrix} \text{Cost measures}\\ \text{Regularizations} \\ \text{Kernelizations} \end{matrix} \right\}$$ as will be described.
Next: basic results for least squares and sketching
`\eps`-approximations
`\tvx` such that $$\norm{\mA\tvx - \vb} \le (1+\epsilon) \norm{\mA\vx^* - \vb},$$ where `\vx^*\equiv \argmin_{\vx\in\reals^d} \norm{\mA\vx - \vb}`
The above will be the main focus here, but also of interest (maybe more interest) is minimizing `\norm{\tvx - \vx^*}`;
cf. section on pre-conditioned least squares.
Sketching Matrices:
Oblivious Subspace Embeddings
(Earlier, some distributions where `\E[\norm{\mS\vy]}^2] = \norm{\vy}^2`.)
a matrix `\mS ` is a subspace `\eps`-embedding for `\mA ` if `\mS ` is an `\eps`-embedding for `\im(\mA )= \{\mA\vx\mid\vx\in\R^d\}`. That is, $$\norm{\mS\mA\vx }= (1\pm\eps)\norm{\mA\vx }\text{ for all }\vx\in\R^d.$$ `\mS\mA` will be called a "sketch".
- A probability distribution `\cal D` over matrices `\mS\in\R^{m\times n}`, so that
- For any unknown but fixed matrix `\mA`,
`\mS ` is a subspace `\eps`-embedding for `\mA `, with high-enough probability.
Sketch and solve

Generic scheme using sketching:
compute `\mS\mA` and `\mS\vb`
return `\tvx := \argmin_{\vx\in\R^d} \norm{\mS(\mA\vx-\vb)}`
For least squares, the sketched problem is easy
But a similar approach applies to harder problems,
yielding greater speedup
Subspace embeddings for sketch and solve
Letting $$\begin{align*} \tvx\equiv & \argmin_{\vx\in\R^d}\norm{\mS (\mA\vx -\vb)} \\ \vx^*\equiv & \argmin_{\vx\in\R^d}\norm{\mA\vx -\vb} \end{align*}$$ when `\eps\le 1/3` $$ \norm{\mA\tvx-\vb} \le (1+3\eps)\norm{\mA\vx^*-\vb} $$
$$ \begin{align*} \norm{\mA\tvx-\vb} & \le\frac{\norm{\mS (\mA\tvx-\vb)}}{1-\eps} \le\frac{\norm{\mS (\mA\vx^*-\vb)}} {1-\eps} \le\norm{\mA\vx^*-\vb}\frac{1+\eps}{1-\eps}, \end{align*}$$
and so for `\eps\le 1/3`, `\norm{\mA\tvx-\vb}\le\norm{\mA\vx^*-\vb}(1+3\eps)`.
yields a good solution in the original space.
Good sketching matrices
- Speed of computation of `\mS`
- Speed of computation of `\mS\mA`
- Sketching dimension `m`,
where `\mS\in\R^{m\times n}`
- time for `\mS\mA` is `O(ndm)`, `m=\tO(d/\eps^2)`:
`\quad` Johnson-Lindenstrauss (JL), i.i.d subGaussians - `\tO(nd)`, `m = \tO(d/\eps^2)`:
`\quad` Fast JL, Subsampled Randomized Hadamard - `\tO(\nnz{\mA})`, `\tO(d^2/\eps^2)`:
`\quad` Countsketch, a.k.a. sparse embeddings
`\quad` cf. "feature hashing", maybe "random indexing" - `\tO(\nnz{\mA}) +\tO(d^3)`, `\tO(d/\eps^2)`:
`\quad` Two-stage - `\tO(\nnz{\mA}f(\kappa))`, `\tO(d^{1+\kappa}/\eps^2)`:
`\quad` OSNAPs - `O(\nnz{\mA}\log(d)/\eps)`, `O(d\log(d)/\eps^2)`:
`\quad` Sparse embeddings - time to find `\mS` is `O(\nnz{\mA}\log(d)) + \tO(d^3)`,
`m=O(d\log(d)/\eps^2)`
`\quad` Leverage-score sampling
Actually even better: to `\poly(\rank(A))`,
that is, polynomial in the dimension of the `\im(\mA)`.
Algorithmic problems beyond regression
Sketching can be applied to a variety of NLA problems- Rank: `\tO(\nnz{\mA}) + \rank(\mA)^3` (cf. rank condensers)
- `\rank(\mA)\equiv \dim (\im(\mA))`
- Trace
- `\trace(\mA) \equiv \sum_{i\in[n]} a_{ii}\quad`(only defined for square `\mA`, `n=d`)
- Regression
- `\tO(nd) + \tO(d^3)\poly(1/\eps)`
- `\tO(\nnz{\mA}) + \tO(d^3)\poly(1/\eps)`
- `\tO(\nnz{\mA})\log(1/\eps) + \tO(d^3)\poly(\log(1/\eps))`
- `\tO(\nnz{\mA} + \tO(d^3)\poly(1/\eps))`
- Low-rank approximation
- `\tO(\nnz{\mA}) + O(n+d)\poly(k/\eps) + \poly(k/\eps)`
- Leading eigenvalues
- `\tO(\nnz{\mA}) + \poly(k/\eps)`
- Canonical correlation analysis
- `\tO(\nnz{\mA}+\nnz{\mB}) + \tO(d^3)\poly(1/\eps)`
- CUR decomposition
- Dimensionality reduction for `k`-means
No dependence on condition number, incoherence, or other `\mA` numerical properties
May require large `\nnz{\mA}\gg d` and/or not-too-small `\eps` to be "near-linear"
A sample of other uses of sketching
- Matrix-free computations: using only matrix-vector products
- E.g., rank-`k` approx., `\eps` relative error, `\tO(k\eps^{-1/3})` matrix-vector products
- Hyperdimensional computing (Vector Symbolic Architectures)
- Low-rank Semidefinite Programming (SDP)
- For iterative optimizations where the output is low-rank matrix
Approach: maintain sketch that is a good low-rank approximation to iterates
- For iterative optimizations where the output is low-rank matrix
-
Online learning of general recurrent computational graphs such as recurrent network models.
- Independent invention of sketching
- Quantum-inspired algorithms: comparable to quantum in an apples-to-apples comparison [T19] [CCHLW22] [BT23]
More `\tO(\nnz{\mA})`, not using sketching
- Elementwise sampling plus iterative methods, for
- Low-rank approximation [BJS14]
- Robust PCA [NNSAJ14]
- Matrix completion [H13][JNS13][HW14]
- Need numerical conditions on matrix (incoherence)
- Matrix completion
- Cost on error `\mE` is not `\norm{\mE}_F^2` but `\norm{\mE}_\Omega \equiv
\sum_{(i,j)\in\Omega} E_{ij}^2`
- For `\Omega\subset [n]\times[d]`
- Random `\Omega\implies` can `\approx` let missing entries be zero
- `\poly(\log(1/\eps))` instead of `\poly(1/\eps)`
- Cost on error `\mE` is not `\norm{\mE}_F^2` but `\norm{\mE}_\Omega \equiv
\sum_{(i,j)\in\Omega} E_{ij}^2`
Extension: kernelization
That is, linearizing non-linear problems
- Map rows `\mA_{i*}` to `\phi(\mA_{i*})` in higher dimension
- For example, add values `a_{i1}a_{i2}` for each `i` to capture interation of two variables
(That is, a new column comprising the entrywise product of `\mA_{*1}` and `\mA_{*2}`) - Change geometry to discount large distances (Gaussian kernel)
- For example, add values `a_{i1}a_{i2}` for each `i` to capture interation of two variables
- Map `\phi(\mA_{i*})` to lower dimension, preserving `\phi(\mA_{i*})^\top\phi(\mA_{j*})`
- And so, a kind of sketching
Extension: robustness
Least squares is not very robust, fits with other measures are better
- Fitting to black dots together with green dot
- Red line from least-squares
- The green point can exercise a lot of leverage
- Green line is for `\ell_1` regression `M(z)=|z|` above
- `\tO(\nnz{\mA}) + \poly(d/\eps)` [C05][LMP13][CW13][CohP14]
- And much since
Extension: regularization
Find $$ \min_{\vx \in \R^d} \norm{\mA\vx-\vb}^2 \color{green}{ + \lambda\norm{\vx}^2} $$
Regularization reduces large variations in `\vx`, lowers sample complexity
Course outline
- "Some" "basics"
- Oblivious sketching matrices with independent entries
- Approximate Matrix Multiplication (AMM)
- AMM and Embedding
- Countsketch
- Least-squares and AMM
- Pre-Conditioned Least Squares
- Sampling: length-squared and leverage-score
- Subsampled Randomized Hadamard Transform
- Multiple-response least-squares regression, low-rank approximation
- Oblivious sketches: Sub-Gaussian Matrices
- Trace Estimation (Shashanka)
- Subspace iteration, Krylov methods (Shashanka)
- (Maybe) Random Fourier features
Next week:
- Tensor CP Foundations (Tammy)
- Tensor CP randomized algorithms (Tammy)
- Tucker decomposition (Misha + Lior)
- T-product (TSVD) decomposition (Misha + Lior)
Some basics
Orthonormal matrices, projection
its columns are unit vectors, and are pairwise orthogonal. (This terminology is not used by everyone.)
If `\mU` is orthonormal and square, it is orthogonal, and `\mU\mU^\top=\Iden`
A symmetric matrix `\mP` of the form `\mP_\mU=\mU\mU^\top` (or just `\mP`) is an orthogonal projection matrix, and `\mP\mP=\mP` .
(We'll just say "projection", but, not all projections are orthogonal.)
then `\norm{\mU\vy} = \norm{\vy}`.
`\quad\bmP\equiv \Iden-\mP` is also a projection
`\quad\mP\bmP = 0 = \bmP\mP`
`\quad\norm{\vx}^2 = \norm{\mP\vx}^2 + \norm{\bmP\vx}^2\quad` (a.k.a. the Pythagorean theorem)
`\quad\norm{\mP}_F^2=\sum_{i,j} p_{ij}^2 = \rank(\mP)`.
The singular value decomposition
`\mU\in\R^{n\times n}`, `\mSig\in\R^{n\times d}`, and `\mV\in\R^{d\times d}`
such that $$\mA = \mU\mSig\mV^\top,$$ where
- `\mU^\top \mU = \Iden_n\quad` (`\mU` is an orthogonal matrix)
- `\mV^\top \mV = \Iden_d\quad` (`\mV` is an orthogonal matrix)
- `\mSig` is a diagonal matrix (`\sigma_{ij}=0` if `i\ne j`),
and has nonnegative entries `\mSig_{ii} = \sigma_i(\mA) \ge 0` on the diagonal, for `i\in[n\wedge d]` with `\sigma_i` nondecreasing in `i`
`\quad`(Here `\mV_{*i}^\top=[\mV_{*i}]^\top`, the transpose of the `i`'th column of `\mV`.)
often the SVD is written as $$\mA = \mU\mSig\mV^\top,$$ where `\mU\in\R^{n\times r}`, `\mSig\in\R^{r\times r}`, and `\mV\in\R^{d\times r}`,
with the parts that contribute zero omitted. Here `\mSig` is invertible.
Eigendecomposition
there are matrices
`\mU\in\R^{n\times n}` and `\mLam\in\R^{n\times n}`
such that $$\mW = \mU\mLam\mU^\top,$$ where
- `\mU^\top \mU = \Iden_n\quad` (`\mU` is an orthogonal matrix)
- `\mLam` is diagonal, and has entries `\lambda_{ii} = \lambda_i(\mA)` on the diagonal, for `i\in[n]` with `\lambda_i` nondecreasing in `i`
say that `\vy` and `\lambda` are an eigenvector and eigenvalue pair for `\mW`.
For `\mW` with eigendecomposition `\mW=\mU\mLam\mU^\top`,
`\mW\mU_{*i} = \mU\mLam\mU^\top\mU_{*i} = \mU\mLam\ve_i = \mU \lambda_{ii}\ve_i = \mU_{*i}\lambda_{ii}`,
so `\mU_{*i}` and `\lambda_{ii} = \lambda_i(\mA)` are an eigenvector/eigenvalue pair.
The normal equations, the Moore-Penrose pseudo-inverse
That is, `\vz^\top\mA^\top(\mA\vx^*-\vb)=0` for any `\vz`, so the residual `\mA\vx^*-\vb \perp\im(\mA)`
where `\mSig^+` has nonzero entry `\sigma_i(\mA)^{-1}` in place of `\sigma_i(\mA)`
`\mA\mA^+\mA = \mA`
`\mA^+\mA\mA^+=\mA^+`
`\mA^+\mA = \Iden` when `\rank(\mA)= d` (`\mA` has full column rank)
`\mA^+ = (\mA^\top\mA)^+\mA^\top`, consistent with the normal eq.
`\mA^+\vb = \argmin_\vx\norm{\mA\vx - \vb}` (Also: mininum norm solution when there are many solutions)
`\mA^\top\mA\mA^+ = \mA^\top` (so `\mA^\top\mA\mA^+\vb = \mA^\top \vb`, consistent with the normal equations for `\mA^+\vb`)
`\mA\mA^+ = \mU\mU^\top=\mP_\mU` for `\mA=\mU\mSig\mV^\top` (thin), projection onto `\im(\mU)=\im(\mA)`.
`\mA^+\mA = \mV\mV^\top = \mP_\mV`, projection onto `\im(\mV)=\im(\mA^\top)`, the rowspace of `\mA`
`\mP_\mV = \mA^\top\mA^{+\top}`, so `\mA^\top\mA^{+\top}\mA^+\mA=\mA^+\mA`.
`\quad` (Where `\mA^{+\top} = (\mA^+)^\top`. This will matter, eventually.)
The `QR` decomposition
there is `\mQ\in\R^{n\times d}` and `\mR\in\R^{d\times d}` where
- `\mA = \mQ\mR`
- `\mQ` has orthonormal columns, so `\mQ^\top\mQ = \Iden_d`
- `\mR` is upper triangular, so `r_{ij}=0` for `i\gt j`
That is, `\im(\mQ)=\im(\mA)`, the columns of `\mQ` are an orthonormal basis for `\im(\mA)`.
`\mQ` and `\mR` can be computed in `O(nd^2)` time (via e.g. Gram-Schmidt orthogonalization).
The decomposition can be used for least squares:
`\mR^{-1}\mQ^\top\vb = \argmin_\vx\norm{\mA\vx - \vb}`, and:
`\quad`computing `\mQ^\top\vb` takes `O(nd)` time
`\quad`multiplying by `\mR^{-1}`, or really, solving `\mR\vx = \mQ^\top\vb`, takes `O(d^2)` time.
The spectral norm and eigenvalues
then there is `\lambda` so that `\mA^\top\mA\vy_* = \lambda\vy_*`, that is, `\vy_*` and `\lambda` are an eigenvector and eigenvalue pair for `\mA^\top\mA`.
$$\vy_* = \argmax_{\vy} \min_\mu \norm{\mA\vy}^2 + \mu*(\norm{\vy}^2 -1),$$ and setting the gradient with respect to `\vy` to zero, $$2\mA^\top\mA\vy = 2\mu\vy,$$ so `\vy_*` must satisfy this condition, with `\lambda=\mu`.
It turns out that `\max_{\norm{\vy}=1} \norm{\mA\vy}^2 = \sigma_1(\mA)^2`, so `\sigma_1(\mA)^2 = \lambda_1(\mA^\top\mA)`.
The trace
meaning they have the right number of rows/columns to multiply/add.
`\trace(\mA\mB) = \trace(\mB\mA)`
`\qquad` So `\trace(\mA\mB\mC\mD) = \trace(\mD\mA\mB\mC)\qquad` (but `\bcancel{\trace(\mA\mB\mC\mD) = \trace(\mA\mC\mB\mD)}`)
`\trace(\mA+\mB) = \trace(\mA) + \trace(\mB)` (when conformable for addition)
`\E[\trace(\mX)] = \trace(\E[\mX])`
`\trace(\mA^\top) = \trace(\mA)`
`\trace(\mA^\top\mA) = \norm{\mA}_F^2 = \sum_{i,j} a_{ij}^2` (`\mA` need not be square)
`\trace(\mB\mA\mB^{-1}) = \trace(\mB^{-1}\mB\mA)= \trace(\mA)`, for invertible `\mB`
`\trace(\mA) = \trace(\mLam)` for eigendecomposition `\mA = \mU\mLam\mU^\top`
Then `\E[\vs^\top\mA\vs]=\trace(\mA)`.
`\trace(\mA) = \trace(\mA\E[\vs\vs^\top]) = \trace(\E[\mA\vs\vs^\top]) = \E[\trace(\mA\vs\vs^\top)] = \E[\trace(\vs^\top \mA \vs)] = \E[\vs^\top \mA \vs]`
Norms !
Suppose we have a vector space over the reals, and `\norm{\vx}` is a real-valued function.
A seminorm with this property is a norm.
Hereafter, we use this notation for vectors and matrices
and write`\norm{\vx}` for the Euclidean norm `\norm{\vx}_2`.
Some norms: matrices
(With `p` omitted when `p=2`, `d` omitted when in context).
`\norm{\mA}_F = \sqrt{\sum_i \sigma_i(\mA)^2}`
`\norm{\mA}_2 = \sigma_1(\mA)`
`\norm{\mA\mB}_\xi \le \norm{\mA}_2*\norm{\mB}_\xi`, for `\xi \in \{F,\cN, 2\}`
Some norms: random variables
(Using `\norme{\cdot}` to distinguish moment norms from matrix/vector.)
` \norme{X+Y}_p \le \norme{X}_p + \norme{Y}_p` (Minkowski),
and for `\alpha\in\R`, `\norme{\alpha X}_p = |\alpha|*\norme{X}_p`.
That is, if also `\E[X]=\E[Y]=0`, then `\norme{X+Y}_2 = \sqrt{\norme{X}_2^2 + \norme{Y}_2^2}`, which is `\le \norme{X}_2 + \norme{Y}_2`.
If `\norme{X}_{\psi_2}` is bounded, `X` is sub-Gaussian.
Matrix norms from sets: relation to spectral norms and embedding
let `\norm{\mW}_\cN \equiv \sup\{|\vx^\top\mW\vx|/\norm{\vx}^2 \mid \vx\in\cN, \vx\ne 0\}`
so when `\cN\subset\cS`, `\norm{\mW}_\cN \equiv \sup_{\vx\in\cN} |\vx^\top\mW\vx|`.
the distortion (error) of `\norm{\mB\vx}^2` in estimating `\norm{\vx}^2`.
`\norm{\symd{\mB}}_\cN \le\beta \implies \mB` is a `\beta`-embedding of `\cN\implies \norm{\symd{\mB}}_\cN \le 3\beta `.
If `\norm{\symd{\mB}}_\cS \le\beta` then `\mB` is a `\beta`-embedding of `\R^d`.
that is, `\norm{\mB\vx}^2 = (1\pm\beta)\norm{\vx}^2`, so `\norm{\mB\vx} = (1\pm\beta)\norm{\vx}`.
The other implication follows using `(1+\beta)^2 \le 1+3\beta` and `(1-\beta)^2 \ge 1-3\beta`.
The last claim uses homogeneity of `\norm{\cdot}`.
`\norm{\mW}_2^2 = \sup_{\vy\in\cS} \norm{\mW\vy}^2 = \sup_{\vy\in\cS} \norm{\mU\mLam\mU^\top\vy}^2 = \sup_{\vx\in\cS} \norm{\mLam\vx}^2 = \sup_{\vx\in\cS} \sum_i \lambda_{ii}^2 x_i^2 = \sup_i \lambda_{ii}^2`.
So `\norm{\mW}_2 = \sup_i |\lambda_{ii}|`.
Also `\norm{\mW}_\cS = \sup_{\vy\in\cS} |\vy^\top\mW\vy| = \sup_{\vy\in\cS} |\vy^\top\mU\mLam\mU^\top\vy| = \sup_{\vx\in\cS} |\vx^\top\mLam\vx| = \sup_{\vx\in\cS } |\sum_i \lambda_{ii}x_i^2|`,
so `\norm{\mW}_\cS = \sup_i |\lambda_{ii}|` as well.
From `\norm{\mW}_\cN` to `\norm{\mW}_2`: `\eps`-nets
- `\cN= \cN(\epsilon)` is an `\epsilon`-net of set `\cal P` if it is both an:
- `\epsilon`-packing: all `p\in\cN` at least `\epsilon` from `\cN`
- `D(p,\cN\setminus\{p\})\ge\epsilon` for `p\in\cN`
- `\epsilon`-covering: all `p\in\cal P` at most `\epsilon` from `\cN`
- `D(p,\cN)\le\epsilon` for `p\in\cal P`, so `D(\cN,{\cal S})\le\epsilon`
- We only really need the covering property, but a maximal packing is a minimal covering
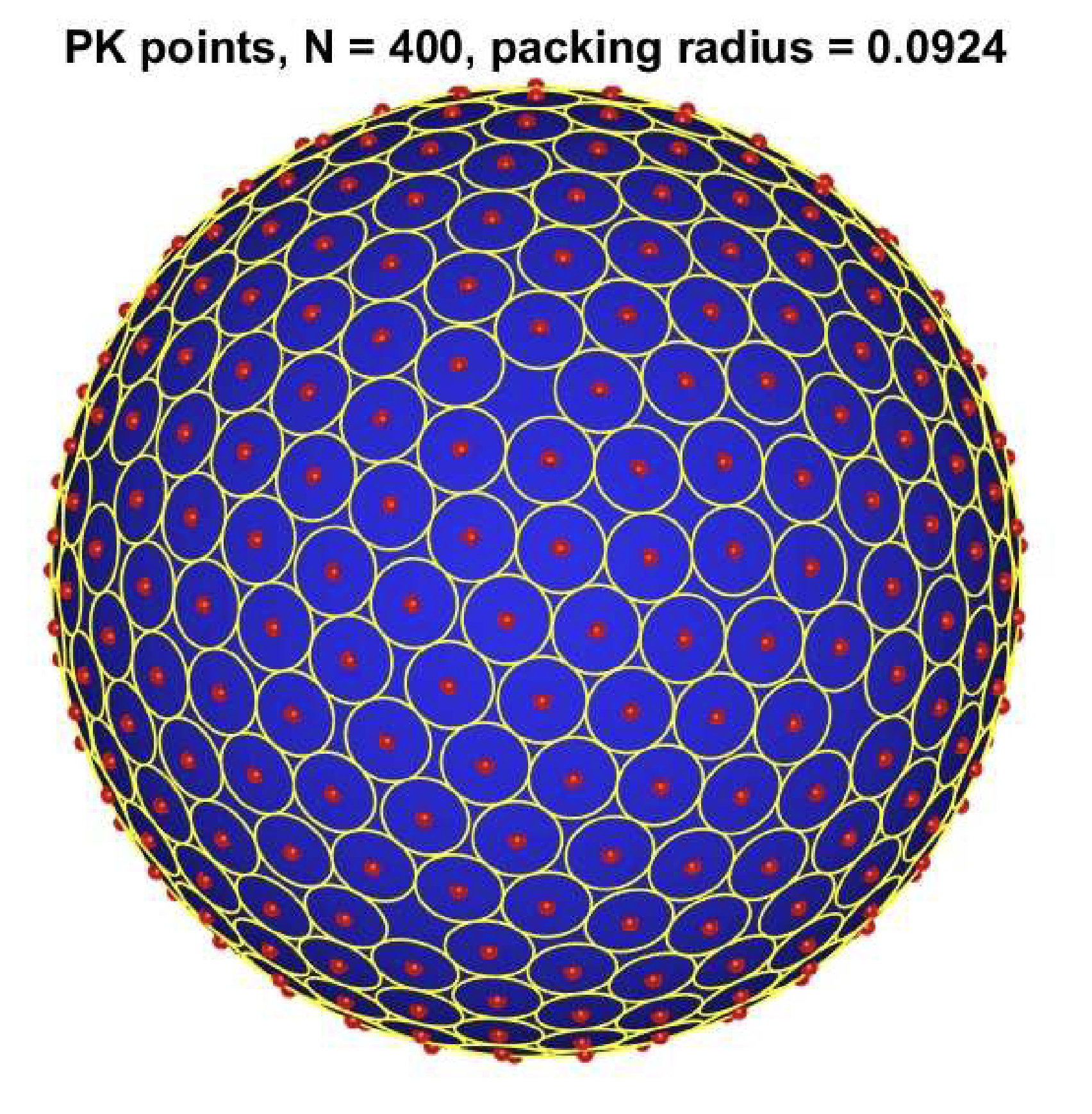
`\norm{\mW}_{\cN_\eps}\approx\norm{\mW}_\cS = \norm{\mW}_2`
if matrix `\mW ` is symmetric, then $$(1-2\eps)\norm{\mW }_2\le\norm{\mW }_{\cN_{\eps}}\le \norm{\mW}_\cS = \norm{\mW }_2.$$ and so if `\mB` is a `\beta`-embedding of `\cN_{\eps}`, where `\beta:= \norm{\symd{\mB}}_{\cN_\eps}`,
then it is a `\beta/(1-2\eps)`-embedding of `\cS`, and so of `\R^d`.
Since `\cN_\eps` is an `\eps`-net, there is `\vz` with `\norm{\vz}\le\eps` and `\vy -\vz\in\cN_{\eps}`.
We have`\begin{align*} \norm{\mW }_2 & = | \vy^\top\mW\vy | = | (\vy -\vz)^\top\mW (\vy -\vz) +\vz^\top\mW\vy +\vz^\top\mW (\vy -\vz) | \\ & \le | (\vy -\vz)^\top\mW (\vy -\vz)| + |\vz^\top\mW\vy| + |\vz^\top\mW (\vy -\vz) | \\ & \le \norm{\mW }_{\cN_{\eps}} + \norm{\vz}*\norm{\mW\vy} + \norm{\vz}*\norm{\mW (\vy -\vz)} \\ & \le\norm{\mW }_{\cN_{\eps}} + 2\eps\norm{\mW }_2.\qquad\qquad (\norm{\vy}=\norm{\vy-\vz}=1) \end{align*}`
So `(1-2\eps)\norm{\mW }_2 \le\norm{\mW }_{\cN_{\eps}}`, as claimed.
Oblivious sketching matrices
with independent entries
The advantages of obliviousness
does not depend on the input data.
- Construct `\mS ` without knowing input `\mA `
- Streaming: when an entry of `\mA ` changes, `\mS\mA ` is easy to update
- Distributed: if each processor `p` has matrix `\mA^{(p)}` and `\mA = \sum_p\mA^{(p)}`:
- Compute `\mS\mA^{(p)}` at each processor
- Ship to master for summation
Analysis advantages:
condition `\cE` holds for `\im(\mA)` iff it holds for `\im(\mU)`.
So for analysis of oblivious sketching, WLOG `\mA` can be assumed orthonormal.
Independent Gaussian sketching matrices: embedding one vector
Recall the sufficient conditions for norm estimation vectors.
If `\vg\in\R^n` has entries that are independent `\cN(0,1)`,
then `\vg^\top\vy\sim\cN(0,\norm{\vy}^2)`
Also, a sum of independent Gaussians is Gaussian, and a scalar multiple of a Gaussian is Gaussian.
If `\mG\in\R^{m\times n}` has independent entries `g_{ij}\sim\cN(0, 1/m)`, then
$$\Prob\{|\,\norm{\mG\vy}^2 - 1| \ge \eps\} \le 2\exp(-\eps^2m/16).$$
That is, with high prob., `\mG` `\eps`-embeds unit `\vy\in\R^n`, and so any fixed `\vy\in\R^n`.
The standard bounds for the concentration of a `\chi^2_m` random variable `X` about its mean `m` imply $$\Prob\{|X-m|\ge 2\sqrt{m\alpha} + 2\alpha\} \le 2\exp(-\alpha).$$ Scaling by `1/m`, and letting `\alpha=\eps^2m/16`,
so that `2\sqrt{\alpha/m} + 2\alpha/m\le\eps`, the claim follows.
I.I.D. sketching matrices: embedding `\im(\mA)`
There is `m=O(\eps^{-2}d\log(1/\delta))` so that
If `\mS\in\R^{m\times n}` is randomly chosen from a fixed (oblivious to `\mA`) distribution with the property that
`\quad\mS` is an `\eps/6`-embedding of `\vy` with failure prob. at most `\delta'\equiv K_1\exp(-K_2\eps^2m)`, for some `K_1,K_2 \gt 0`,
then
`\quad\mS` is an `\eps`-embedding of `\im(\mA)` with failure prob. at most `\delta`.
for some `\eps_0 > 0` to be determined, pick an `\eps_0`-net `\cN=\cN_{\eps_0}\subset\cS`;
for each `\vx\in\cN_{\eps_0}`, `\vy=\mA\vx\in\im(\mA)` is a unit vector (using `\mA^\top\mA=\Iden` and `\norm{\vx}=1`)
Let `\mW := \mA^\top\mS^\top \mS \mA - \Iden_d`,
so that `|\,\norm{\mS\vy}^2 - 1| = |\vy^\top\mS^\top\mS\vy - \vy^\top\vy| = |\vx^\top\mA^\top\mS^\top\mS\mA\vx - \vx^\top\mA^\top\mA\vx| = |\vx^\top\mW\vx|,` and thus
`\quad\norm{\mW}_{\{x\}}\le \eps/2` with failure prob. `\le\delta'`, from the hypothesis.
Applying this to all vectors in `\cN_{\eps_0}` and a union bound,
`\quad\norm{\mW}_{\cN_{\eps_0}} \le\eps/2` with failure prob. `\le\delta'|\cN_{\eps_0}|`.
Using the relation between `\norm{\mW}_\cS` and `\norm{\mW}_{\cN_{\eps_0}}` and the bound for `|\cN_{\eps_0}|`,
`\quad\norm{\mW}_\cS\le (\eps/2)/(1-\eps_0)` with failure prob. `\le\delta'|\cN_{\eps_0}|\le (1+\frac{2}{\eps_0})^d K_1\exp(-K_2\eps^2m)`
For fixed `\eps_0`, there is `m=O(\eps^{-2}d\log(1/\delta))` so that the failure probability is at most `\delta`.
For `\eps_0\le 1/2`, this implies`\norm{\mW}_\cS\le 2(\eps/2)=\eps`, and so the claim of the theorem.
If `\mG\in\R^{m\times n}` has independent entries `g_{ij}\sim\cN(0, 1/m)`
then there is `m=O(\eps^{-2}d\log(1/\delta))` so that with failure probability at most `\delta`,
`\mG` is an `\eps`-embedding of `\im(\mA)`.
If `\mS\in\R^{m\times n}` has independent entries `s_{ij}= \pm 1/\sqrt{m}`,
then there is `m=O(\eps^{-2}d\log(1/\delta))` so that with failure probability at most `\delta`,
`\mS` is an `\eps`-embedding of `\im(\mA)`.
If `\mS\in\R^{m\times n}` has independent entries `s_{ij}\sim` sub-Gaussian, with `\E[\mS^\top\mS]=\Iden`,
then there is `m=O(\eps^{-2}d\log(1/\delta))` so that with failure probability at most `\delta`,
`\mS` is an `\eps`-embedding of `\im(\mA)`.
Aside 1/3: Gaussian Width and Gordon's theorem
Note that `\sup_{\vg\in\cS}[\ldots]` is the (geometric) width, and `\E_{\vg\sim\mathrm{Unif}(\cS)}[\ldots]` is the mean width.
There are many variant definitions of Gaussian width, we will use the following.
- `w(\R^n)\le\sqrt{n}` `\qquad`
- `w(\cL)\le\sqrt{k}` for `\cL` a `k`-dimensional subspace `\qquad` (Hint: rotation invariance)
- `w(\cR)\le\sqrt{2\log|\cR|}` for finite `\cR` `\qquad` (Hint: bound `\E[\exp(t*w(\cR))]`.)
Note that for finite `\cR`, its width can be much smaller than the given bound
Aside 2/3: Gordon's theorem and Johnson-Lindenstrauss
if `\mG\in\R^{m\times n}` has independent entries `g_{ij}\sim\cN(0, 1/m)`, then $$\Prob\{\norm{\mG^\top\mG-\Iden}_\cR \ge 2\beta+\beta^2 \} \le \exp(-t^2/2),\text{ where } \beta\equiv \frac{w(\cR)+1+t}{\sqrt{m}}.$$
Then `w(\cP-\cP) \le 2\sqrt{\log|\cP|}`,
and the result follows from applying Gordon's theorem to `\cR=\cP-\cP`:
let `m\gets 9\eps^{-2}(2\sqrt{\log|\cP|} + 1 + t)^2`, so that
`\beta \le \eps/3\implies 2\beta+\beta^2\le \eps`.
(Note: the original, true JL used rows of a random orthogonal matrix. This has roughly the same behavior.)
Aside 3/3: Partial analysis of sign matrices via Schur convexity of moments
Analysis for sign matrices can be via single-vector embedding, or subGaussian analysisOr the Schur convexity of the distortion:
with independent entries `s_{ij}= \pm 1/\sqrt{m}`,
the moments `\E\left[\norm{\mS^\top \mS - \Iden}_{\{\vx\}}^q\right]` of the distortion of `\norm{\vx}` are:
- Schur-concave polynomials in the `x_i^2`
- `\implies` maximum when all `x_i^2` are equal (`\vx` is flat), and moments increase with `n` (making `\vx` even flatter)
- `\implies` for unit `\vx` at most `\E[X^q]`, where `X=\frac1m\norm{Z}^2 -1` for random `Z\in\R^m`, with `Z_i = \frac{1}{\sqrt{n}}\sum_j s_j = \frac{Z'_i- EZ'_i}{\sd[Z'_i]}`, with `Z'_i \sim {\cal B}(n,1/2)`, sign vector `\vs`
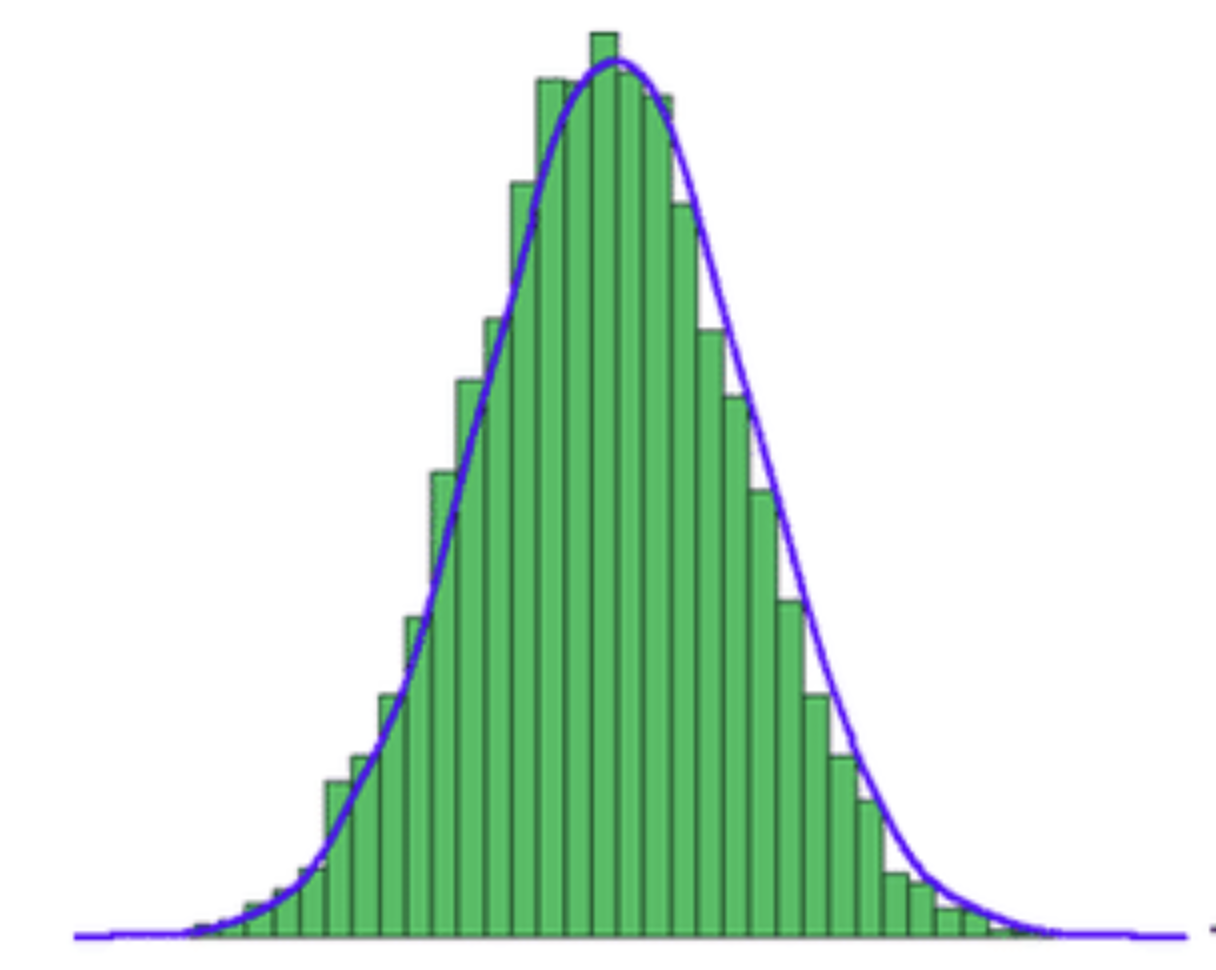
all moments dominated by those for `\cN(0,1)`,
so `Y = m(X+1)\rightarrow \chi^2_m` (and is moment-dominated by it (NPH));
if the moment dominance in this case yielded
`\Pr\{\norm{\mS^\top \mS - \Iden}_{\{\vx\}} \ge t\} \le \Pr\{|\frac1mY - 1|\ge t\} = \Pr\{|Y-m|\ge mt\}`
then the analysis would follow as for as for Gaussian `\mG`.
Multiplication and Embedding
Subspace embedding and Approximate Matrix Multiplication (AMM), revisited
One version of the embedding condition is $$\norm{\mU^\top\mS^\top\mS\mU -\Iden}_2 = \norm{\mU^\top\mS^\top\mS\mU -\Iden}_\cS\le\eps.$$
Since `\mU^\top\mU = \Iden`, this is an AMM condition:
Next: sketches that are good for AMM are embeddings, and
a weaker condition on `\norm{\mS\vy}` still implies AMM
Vector norm preservation moment bound implies AMM
Suppose that when unit `\vy\in\R^n` is picked, and then
sketching matrix `\mS` is chosen (with a distribution oblivious to `\vy`),
that $$\sd[\norm{\mS\vy }^2] \le \eps\sqrt{\delta}/6. $$ Then $$\norm{\mB\mS^\top\mS\mA -\mB\mA}_F\le\eps\norm{\mA }_F\norm{\mB }_F\text{ with failure probability } \delta.$$
Suppose that when sketching matrix `\mS` is chosen (with an oblivious distribution), $$\norm{\mB\mS^\top\mS\mA -\mB\mA}_F\le\eps\norm{\mA }_F\norm{\mB }_F\text{ with failure probability } \delta.$$ Then `\mS ` is an `\eps r`-embedding of `\im(\mA)` with failure probability `\delta`.
(Orthonormal `\mA\in\R^{n\times r}` has `\norm{\mA}_F^2 = \sum_{j\in[r]}\sum_{i\in[n]} u_{ij}^2 = \sum_{j\in[r]} 1 = r`.)
Example: Gaussians for multiplication
then `\sd[\norm{\mG\vy}^2] \le \sqrt{2/m}`
If `\mG\in\R^{m\times n}` has ind. entries `g_{ij}\sim\cN(0,1/m)`,
then there is `m=O(\eps^{-2}\delta^{-1})` so that $$\norm{\mB\mG^\top\mG\mA -\mB\mA}_F\le\eps\norm{\mA }_F\norm{\mB }_F\text{ with failure probability } \delta.$$
From one vector to two matrices
with `\tva \equiv \va/\norm{\va}` and `\tvb \equiv \vb/\norm{\vb}`, \begin{align} 2\sd[{\vb^\top\mW\va}] & \le \sd[{(\vb+\va)^\top\mW(\vb+\va)}] + \sd[{\vb^\top\mW\vb}] + \sd[{\va^\top\mW\va}]\nonumber\\ & = \norm{\vb}\norm{\va}\left(\sd[{(\tvb+\tva)^\top\mW(\tvb+\tva)}] + \sd[{\tvb^\top\mW\tvb}] + \sd[{\tva^\top\mW\tva}]\right).\label{eq bilin} \end{align}
From embedding to matrix multiplication: tail
The claim of a few slides ago:Suppose that when unit `\vy\in\R^n` is picked, and then
sketching matrix `\mS` is chosen (with a distribution oblivious to `\vy`),
that $$\sd[\norm{\mS\vy }^2] \le (1/3)\eps\sqrt{\delta}. $$ Then $$\norm{\mB\mS^\top\mS\mA -\mB\mA}_F\le\eps\norm{\mA }_F\norm{\mB }_F\text{ with failure probability } \delta.$$
For `p\gt 2`
The results generalizeComparing the two reductions from matrices to vectors
We've seen two ways to go from embeddings of single vectors to embeddings of subspaces.Let `r = \norm{\mU}_F^2 = \rank(\mA)`, `\mU` an orthonormal basis for `\im(\mA)`.
`\begin{align*} & \Prob\{\norm{\symd{\mS}}_{\{\vy\}} \ge \eps\} \le e^{-m\eps^2} \\ & \implies \Prob\{\norm{\mU^\top\mS^\top\mS\mU-\Iden}_{\cN_{\eps_0}} \ge \eps\} \le C^r e^{-m\eps^2} \\ & \implies \Prob\{\norm{\mU^\top\mS^\top\mS\mU-\Iden}_2 \ge 2\eps\} \le C^r e^{-m\eps^2} \end{align*}`
`\begin{align*} & \norme{\norm{\symd{\mS}}_{\{\vy\}}}_p \le \eps\delta^{1/p}/3 \\ & \implies \norme{\frac1r\norm{\mU^\top\mS^\top\mS\mU-\Iden}}_p^p \le \eps^p\delta \\ & \implies \Prob\{\frac1r\norm{\mU^\top\mS^\top\mS\mU-\Iden}_2 \ge \eps\} \le \delta \end{align*}`
In each case, a kind of intermediate norm is used:
`\norm{\cdot}_\cN` for `\cN` a `\eps_0`-net in one way,
`\norme{\cdot}_p` in the other
Further Reading
The matrix multiplication results are cribbed from
Jelani Nelson's lecture
notes.
See also:
Daniel M. Kane, Jelani Nelson. Sparser Johnson-Lindenstrauss transforms. SODA, 1195-1206, 2012.
Countsketch
Faster embeddings: countsketch
A sketching matrix of independent Gaussians is good but slow:
- `\mS ` is an embedding with high probability
- For `\mS\in\R^{m\times n}` and `\mA\in\R^{n\times d}`, computing `\mS\mA ` takes `\Omega(mnd)` time
We will show a faster scheme, and use the reduction
Sparse Embeddings
- Adaptation of
CountSketchfrom streaming algorithms - `\mS ` looks like:
`\qquad\qquad\left[\begin{matrix} 0 & -1 & 0 & 0 & +1 & 0 \\ +1 & 0 & 0 & +1 & 0 & 0 \\ 0 & 0 & +1 & 0 & 0 & -1 \\ 0 & 0 & 0 & 0 & 0 & 0 \end{matrix} \right]`
- One random `\pm 1` per column
- Row `\mA_{i*}` of `\mA ` contributes `\pm\mA_{i*}` to one row of `\mS\mA `
Sparse embeddings, more precisely
pick uniformly and independently:
- `h_i\in [m]`
- `s_i\in\{+1,-1\}`
Define `\mS\in\R^{m\times n}` by $$\mS_{h_i, i}\gets s_i, \text{ for } i\in [n],$$ and `\mS_{ji} \gets 0` otherwise
`\vs` is a sign (Rademacher) vector, it does "sign flips"
The vector `\vh` hashes to `m` "hash buckets"
That is, $$\mS_{j*} = \sum_{i:\,h_i=j} s_i \ve_i^\top,$$ so $$ [\mS\mA]_{j*} = \sum_{i:\,h_i=j} s_i \ve_i^\top \mA = \sum_{i:\,h_i=j} s_i \mA_{i*}$$
When `\mS` is a sketching matrix from a sparse embedding distribution,
`\mS\mA` can be computed in `O(\nnz{\mA})` time.
Sparse embeddings, even more



so `s_i=\pm 1` independently with equal probability,
then `\E[(\vs^\top\vy)^2] = \norm{\vy}^2`.
- For `\vy = \mA\vx`, each row of sparse embedding `\mS
`:
- Collects a subset of entries of `\vy ` (into a "bucket")
- Applies random signs
- Adds
- Result is `\E[\norm{\mS\vy}^2] = \norm{\vy }^2`:
- Each bucket squared `\approx` squared norm of its entries
- Splitting into buckets separates big entries
- Smaller variance
- With `n` buckets, don't quite get `\norm{\vy }^2` exactly, always
- (Entry `\rightarrow` Bucket is not one-to-one)
Analysis of sparse embeddings, 1/2
and `\vy` a unit vector, $$\sd[\norm{\mS\vy}^2] \le \sqrt{3/m}.$$
We have
`z_j = [\mS\vy]_j = \sum_{i:\,h_i=j} s_i y_i`,
so
$$\sum_j \E_s[z_j^4] = \sum_{i,i',i'',i''':\, h_i = h_{i'} = \ldots = j} \E_s[s_i y_i
s_{i'} y_{i'} s_{i''} y_{i''} s_{i'''} y_{i'''}]$$
which is zero unless `i` is equal to one of the other three indices,
and the remaining two are equal: there are two equal pairs in the sum. So
$$\E_{s,h}[z_j^4]
= \sum_{i,i'}\Pr\{h_i = h_{i'}=j\}(\text{# equal pairs})y_i^2y_{i'}^2
= \sum_{i,i'}\frac{1}{m^2} 3 y_i^2y_{i'}^2
=\frac{3}{m^2}\norm{\vy }^4 = \frac{3}{m^2}.
$$
and
`\Var[\norm{\mS\vy}^2]
\le\sum_{j\in[m]}\E_{s,h}[z_j^4]
\le\frac{3}{m}.`
Analysis of sparse embeddings, 2/2
We have for `\mS ` a sparse embedding, and unit `\vy `, `\sd[\norm{\mS\vy}^2] \le \sqrt{K/m}`.By the bound for embedding via AMM,
If `K/\sqrt{m}\le\beta\delta^{1/2}`,
then `\mS ` is a `(\beta r)`-embedding with failure probability
`\delta`.
Here `r=\rank(\mA)`.
With `\delta = 1/9`, `\eps/r = \beta\ge 3K/\sqrt{m}` yields
- `\eps\in (0,1)`
- `r\equiv\rank(\mA )`
There is
- `m=O(r^2/\eps^2)`
- `\mS\in\R^{m\times n}` countsketch matrix
such that with failure probablity `1/9`, `\mS ` is an `\eps`-embedding of `\im(\mA )`.
Slightly less sparse embeddings
So far: one nonzero per column.
There are sparse embeddings where
the sketch dimension `m` is smaller, and
the number `s` of nonzeros is slightly larger.
`s=O(\polylog(r)/\eps)` and `m=\tO(r/\eps^2)`, or
`s=O(1/\eps)` and `m=O(r^{1+\gamma}/\eps^2)` for any constant `\gamma \gt 0`.
In practice, small `s\gt 1` has better performance [D15].
Hybrid approaches are also possible, resulting in similar performance for some problems.
Further Reading
The use of Countsketch for subspace embeddings was introduced by:Kenneth L. Clarkson and David P. Woodruff. Low rank approximation and regression in input sparsity time. Proc.45th Annual ACM Symposium on the Theory of Computing (STOC), 81-90, 2013.
The analysis above was given by:Jelani Nelson and Huy L. Nguyen. OSNAP: Faster numerical linear algebra algorithms via sparser subspace embeddings. Proc. 54th Annual IEEE Symposium on Founda- tions of Computer Science (FOCS), 2013.
and byXiangrui Meng and Michael W. Mahoney. Low-distortion subspace embeddings in input-sparsity time and applications to robust linear regression. Proc. 45th Annual ACM Symposium on the Theory of Computing (STOC), 91-100, 2013.
Pre-Conditioned Least Squares
Pre-conditioning least squares
We use the following observation.Let `[\mQ,\mR ] \gets \mathtt{qr}(\mS\mA)`
Then `\mY \gets \mA\mR^{-1}` has singular values `1\pm\eps`.
To solve `\min_\vz \norm{\mA\vz - \vb}`,
we can solve `\min_\vx\norm{\mA\mR^{-1}\vx -\vb}`, that is,
`\vx^* \gets \argmin_\vx\norm{\mY\vx -\vb}` for `\mY = \mA\mR^{-1}`,
and return `\vz=\mR^{-1}\vx^*`.
Why does this help?
We have `\im(\mY)=\im(\mA)`, and `\mY` has (almost)
orthonormal columns.
If `\mY` were orthonormal,
then `\mY^\top\vb = \vx^* \equiv \argmin_\vx \norm{\mY\vx - \vb}^2`,
because `\mY\mY^\top\vb` is the projection of `\vb` onto `\im(\mY)`
This would be fast!
But our `\mY` is not (quite) orthonormal.
Even so, `\mY\mY^\top\vb` is (almost) closest to `\vb` in `\im(\mY)`,
so we might expect `\vb - \mY\mY^\top\vb` to be shorter than `\vb`.
Iterative refinement algorithm for well-conditioned least squares
To solve `\min_\vx\norm{\mY\vx -\vb}`, a classic simple algorithm:
`\norm{\mY (\vx^{(j+1)} -\vx_*)} \le \frac12\norm{\mY (\vx^{(j)} -\vx_*)}`
for small enough `\eps`, where `\vx_*\equiv\argmin_\vx \norm{\mY\vx-\vb}^2`.
$$\begin{align*} \mY (\vx^{(j+1)} -\vx_*) & = \mY (\vx^{(j)} +\mY^\top(\vb-\mY\vx^{(j)}) -\vx_*) \\ & = \mY (\vx^{(j)} +\mY^\top\vb-\mY^\top\mY\vx^{(j)} -\vx_*) \\ & = \mY (\vx^{(j)} +\mY^\top\mY\vx_*-\mY^\top\mY\vx^{(j)} -\vx_*) \qquad (\text{ normal eq.s } \mY^\top\vb = \mY^\top\mY\vx_*) \\ & = (\mY -\mY\mY^\top\mY )(\vx^{(j)}-\vx_*) \\ & = \mU (\mSig -\mSig^3)\mV^\top (\vx^{(j)}-\vx_*), \end{align*}$$ where `\mY = \mU\mSig\mV^\top`, so that `\mY\mY^\top\mY = \mU\mSig^3\mV^\top`.
Since all `\sigma_i = \mSig_{ii} = 1\pm\eps`, we have
`(\Iden-\mSig^2)_{ii} = 1 - \sigma_i^2 = 1 - (1\pm\eps)^2 \le 3\eps\le 1/2`,
for small enough `\eps`, so
$$\norm{\mY(\vx^{(j+1)} -\vx_*)}
\le \norm{\mU \mSig (\Iden -\mSig^2)\mV^\top (\vx^{(j)}-\vx_*)}
\le\frac12\norm{\mY(\vx^{(j)} -\vx_*)}$$
for small enough `\eps`, as claimed.
Least-squares regression, putting it together
We don't compute `\mY`, we don't even compute `\mR^{-1}`.
When we mention `\mR^{-1}\vz` for some `\vz`, we mean "the solution to `\mR\vx = \vz`".
- Input matrix `\mA `
- Target accuracy `\eps`
- Subspace `\eps_0`-embedding matrix `\mS\in\R^{m\times n}` for `\mA `, small enough `\eps_0`
| `j_{\max}\gets O(\log(1/\eps))` | |
| `\mW = \mS *\mA `; | // compute sketch |
| `[\mQ,\mR ] = \mathtt{qr}(\mW )`; | // compute change-of-basis for `\mS\mA ` |
| `\vx^{(0)}\gets 0`; | // initialize |
| for `j\gets 0,1,\ldots,j_{\max}`, `\qquad\vx^{(j+1)}\gets\vx^{(j)} + (\mR^\top)^{-1}\mA^\top (\vb-\mA\mR^{-1}\vx^{(j)})` |
|
| return `\mR^{-1}\vx^{(j_{\max}+1)}`; |
Further Reading
A serious use of sketching for pre-conditioning iterative algorithms was:
Haim Avron, Petar Maymounkov, and Sivan Toledo. Blendenpik: Supercharging LAPACK's Least-Squares Solver. SIAM Journal on Scientific Computing 2010 32:3, 1217-1236.
The above simplified version is from:
Kenneth L. Clarkson and David P. Woodruff. Low rank approximation and regression in input sparsity time. Proc.45th Annual ACM Symposium on the Theory of Computing (STOC), 81-90, 2013.
Length-squared sampling
Sampling rows of a matrix
has rows that are multiples of the natural basis vectors `\ve_i^\top`.
A column sampling matrix is the transpose of a row sampling matrix.
each row of `\mS\mA` is a multiple of a row of `\mA`:
`\small\qquad\left[\begin{matrix} 0 & s_{12} & 0 & 0 & 0 & 0 \\ s_{21} & 0 & 0 & 0 & 0 & 0 \\ 0 & 0 & s_{33} & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0 & s_{46} \end{matrix} \right] \left[\begin{matrix} \mA_{1*}\\ \mA_{2*}\\ \vdots\\ \mA_{n*} \end{matrix} \right] = \left[\begin{matrix} s_{12}\mA_{2*}\\ s_{21}\mA_{1*}\\ s_{33}\mA_{3*}\\ s_{46}\mA_{6*} \end{matrix}\right]`
We generalize the sampling scheme (looking at a single sampling vector `\vs`):
Pick `i\in[n]` with prob. `1/n`, set `s_i\gets \sqrt{n}`.
`\E[s_i^2] = \frac{1}{n}\sqrt{n}^2 + (1-\frac{1}{n})0 = 1`.
Also `s_i\ne 0 \implies s_j=0` for `i\ne j`,
`\quad` so `s_is_j=0`, for `i\ne j`.
Given `\vp\in [0,1]^n`, `\sum_i p_i = 1`.
Pick `i\in[n]` with prob. `p_i`, set `s_i\gets \sqrt{1/p_i}`.
`\E[s_i^2] = p_i\sqrt{1/p_i}^2 + (1-p_i)0 = 1`.
Also `s_i\ne 0 \implies s_j=0` for `i\ne j`,
`\quad` so `s_is_j=0`, for `i\ne j`.
Choices of `\vp`
A sampling matrix `\mS` can be used to:
$$\text{estimate }\mB\mA\approx\mB\mS^\top\mS\mA.$$
When `\mS` has one row, and `\mB` is a vector `\vb^\top`, the estimate is
`b_i s_{1i}^2 \mA_{i*} = \frac{1}{p_i}b_i\mA_{i*}` with probability `p_i`.
If `p_i= b_i^2 = 1/n` for all `i`, and `\norm{\mA_{1*}}^2 \gg` the norms of all other rows,
this can be way off, by missing `i=1`
Repetition (`m\gt 1`) helps, but not that much.
One idea: catch big rows by making `p_i \propto \norm{\mA_{i*}}^2`.
That is,Length-squared sampling
Vector `\vs\in\R^n` is a length-squared sampling vector for `\mA` if
`i\in[n]` is chosen with probability `p_i\gets \norm{\mA_{i*}}^2/\norm{\mA}_F^2`
and `\vs \gets \frac{1}{\sqrt{p_i}}\ve_i`.
Let `\vs\in\R^n` be a length-squared sampling vector for `\mA`.
Then `\E[\mB\vs\vs^\top\mA]=\mB\mA` (unbiased estimator) and $$\E[\norm{\mB\vs\vs^\top\mA - \mB\mA}_F^2] \le \norm{\mA}_F^2\norm{\mB}_F^2.$$
So `\E[\norm{\mB\vs\vs^\top\mA - \mB\mA}_F^2]` is the sum of entrywise variances, and since `\Var[X] = \E[X^2] - \E[X]^2`,
it is at most
`\begin{align*} \E[\norm{\mB\vs\vs^\top\mA}_F^2] & = \sum_{j,k} \E[(\mB_{j*}\vs\vs^\top\mA_{*k})^2] = \sum_{j,k} \E[(\sum_i b_{ji}s_i^2 a_{ik})^2] = \sum_{j,k} \sum_i b_{ji}^2 p_i \frac{1}{p_i^2} a_{ik}^2 \\ & = \sum_{j,k} \sum_i b_{ji}^2 \frac{1}{p_i} a_{ik}^2 = \sum_i \sum_j b_{ji}^2 \frac{1}{p_i} \sum_k a_{ik}^2 = \sum_i \norm{\mB_{*i}}^2\frac{\norm{\mA}_F^2}{\norm{\mA_{i*}}^2} \norm{\mA_{i*}}^2 \\ & = \norm{\mA}_F^2 \sum_i \norm{\mB_{*i}}^2 = \norm{\mA}_F^2 \norm{\mB}_F^2. \end{align*}`
Lowering the variance of AMM
Matrix `\mS\in\R^{m\times n}` is a length-squared row sampling matrix for `\mA` if
each row of `\mS` is `\frac{1}{\sqrt{m}}` times an independently chosen length-squared sampling vector for `\mA`.
A column sampling matrix `\mR` has `\mR^\top` a row sampling matrix for `\mA^\top`.
`\mS\in\R^{m\times n}` a length-squared sampling matrix for `\mA`.
Then `\E[\mB\mS^\top\mS\mA]=\mB\mA` and
$$\E[\norm{\mB\mS^\top\mS\mA - \mB\mA}_F^2] \le \frac{1}{m}\norm{\mA}_F^2\norm{\mB}_F^2.$$
`\mB\mS^\top\mS\mA=\sum_{i\in[m]} \mB\mS^\top_{*i}\mS_{i*}\mA` is the mean of `m` length-squared sampling vector estimators `X^{(i)}` of the form `\mB\vs^\top\vs\mA`. Since they are unbiased, it is unbiased as well.
Also, for any given `j\in[d'],k\in[d]`, the error `X^{(i)}_{jk}` has `\Var[\sum_{i\in [m]} X^{(i)}_{jk}/m] = \sum_{i\in [m]} \Var[X^{(i)}_{jk}]/m] = m\frac{\Var[X^{(1)}_{jk}]}{m^2} = \frac{\Var[X^{(1)}_{jk}]}{m}`.
Summing over `j` and `k`, and using the result for sampling vectors,
this is at most `\frac{1}{m} \norm{\mA}_F^2\norm{\mB}_F^2`, as claimed.
Low-rank approximation via length-squared sampling, 1/2
The product results can be extended to a particular kind of low-rank approximation.
- A row sampler `\mS` and sketch `\mS\mA\in\R^{m_S\times d}` of rows of `\mA`
- A col. sampler `\mR` and sketch `\mA\mR\in\R^{n\times m_R}` of col. of `\mA`
- A matrix `\mZ\in\R^{m_S\times m_R}`
The result is
`\mA\mR\,\mZ\,\mS\mA \approx \mA`, with rank at most `m_S\wedge m_R`.
the columns of `\mC` are Columns of `\mA`, and the rows of `\mR` are Rows of `\mA`.
Why should such an approximation be any good?
- The columns of `\mA\mR` are good representatives of the columns of `\mA`,
so `\mP\mA\approx \mA`, where `\mP=\mP_{\mA\mR}` projects the columns of `\mA` onto `\im(\mA\mR)` - `\mP\mA` can be approximated as `\mP\mS^\top\mS\mA`
- `\mP\mS^\top\mS\mA = [(\mA\mR)(\mA\mR)^+]\mS^\top\mS\mA = [\mA\mR][(\mA\mR)^+\mS^\top][\mS\mA] = \mA\mR\,\mZ\,\mS\mA `, where `\mZ=(\mA\mR)^+\mS^\top`
For computation, this may be more convenient:
`\qquad \mZ = (\mA\mR)^+\mS^\top= ((\mA\mR)^\top\mA\mR)^+(\mA\mR)^\top\mS^\top
= (\overbrace{(\mA\mR)^\top\mA\mR}^{m_R\times m_R})^+ (\overbrace{\mS\mA\mR}^{m_S\times m_R})^\top `
Low-rank approximation via length-squared sampling, 2/2
We will need (cf. other results on `\mA^+`):Let `\mP \equiv \mP_{\mA\mR} = \mA\mR(\mA\mR)^+`, and `\bmP\equiv \Iden - \mP`.
Then `\norm{\bmP\mA}^2_2 \le \norm{\mA\mA^\top - \mA\mR\mR^\top\mA^\top}_2`.
Let `\vx_*` be a unit vector with `\norm{\mA^\top\bmP\vx_*} = \norm{\mA^\top\bmP}_2 = \norm{\bmP\mA}_2`.
`\begin{align*} \text{Then }\norm{\bmP\mA}_2^2 & = \vx_*^\top\bmP\mA\mA^\top\bmP\vx_* \\ & = \vx_*^\top\bmP(\mA\mA^\top - \mA\mR\mR^\top\mA^\top)\bmP\vx_* && \text{added term is zero, as noted above} \\ & \le \norm{\mA\mA^\top - \mA\mR\mR^\top\mA^\top}_2 && \text{Cauchy-Schwartz, }\norm{\bmP}_2=1 \end{align*}`
Then for `\mZ = ((\mA\mR)^\top\mA\mR)^+(\mA\mR)^\top\mS^\top`, $$ \E[\norm{\mA\mR\mZ\mS\mA - \mA}_2^2] \le 2\norm{\mA}_F^2 \left(\frac{1}{\sqrt{m_R}} + \frac{m_R}{m_S}\right)\le \eps\norm{\mA}_F^2,$$ for `m_R=16/\eps^2, m_S=64/\eps^3`.
So `\mA\mR\mZ\mS\mA = \mP\mS^\top\mS\mA`. We have `\begin{align*} & \norm{\mA\mR\mZ\mS\mA - \mA}_2^2 \\ & \le 2[\norm{\mP\mS^\top\mS\mA - \mP\mA}_2^2 + \norm{\mP\mA - \mA}_2^2] && \Delta\text{ ineq, }(a+b)^2\le 2a^2+2b^2 \\ & \le 2[\norm{\mP\mS^\top\mS\mA - \mP\mA}_2^2 + \norm{\mA\mA^\top - \mA\mR\mR^\top\mA^\top}_2], && \text{From projection to AMM} \end{align*}`
which in expection, by applying sampling AMM bounds, is at most twice $$ \frac{1}{m_S}\norm{\mA}_F^2\norm{\mP}_F^2 + \frac{1}{\sqrt{m_R}}\norm{\mA}_F^2, \text{ giving the bound, using }\norm{\mP}_F^2 \le m_R. $$
there are `m_R = O(\delta^{-2}\eps^{-4})`, `m_S=(\delta^{-3}\eps^{-6})`, so that $$\Pr\{\norm{\mA\mR\mZ\mS\mA - \mA}_2 \ge \eps\norm{\mA}_F\} \le \delta. $$
- Big polynomials in `1/\eps`
- Spectral norm bounded by Frobenius
- Bound in terms of `\norm{\mA}_F`: not relative to best approximation
Running time, quantum-inspired-style
There is a data structure supporting changes to single entries of `\mA` in `O(\log(nd))` time, such that given that data structure, a CUR decomposition of `\mA`, as just above, can be computed in `\tO((n\wedge d)(1/\eps)^{O(1)})` time, for fixed `\delta >0`.
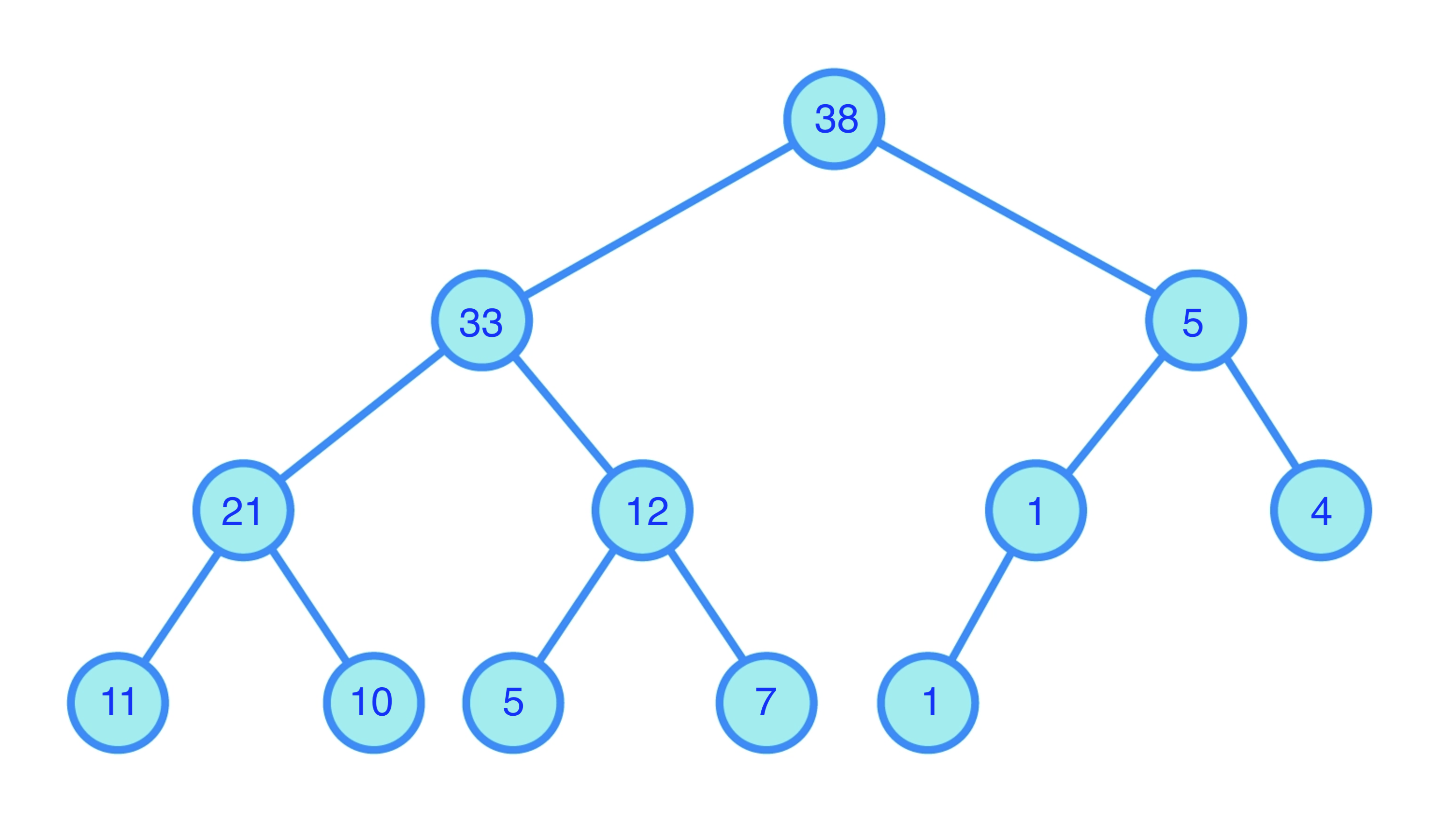 Each tree supports maintenance of a collection of `k` real values (weights).
Each tree supports maintenance of a collection of `k` real values (weights).The `k` weights are assigned to the leaves
Each internal node has weight equal to the weights of the leaves of its subtree
Such a tree can be:
- Updated (new weight added or changed) in `O(\log k)` time
- Used to pick a weight `w_i` with probability `w_i/\sum_j w_j`.
Maintain a tree for each set of squared lengths:
- Rows of `\mA`
- Columns of `\mA`
If `n\gt d`, work with the transpose, so WLOG `n\le d`.
The data structure is a collection of binary trees.
- Using these trees, pick `\mS` and `\mR`
- Obtain `\mZ` by applying `((\mA\mR)^\top\mA\mR)^+` to `(\mS\mA\mR)^\top`
- Return `\mS`,`\mR`, and `\mZ`
Step 1 takes
`\quad O((m_S+m_R)\log(nd))` time;
Step 2 takes
`\quad O(n m_R^2)` to compute `(\mA\mR)^\top\mA\mR`,
`\quad O(m_R^3)` to compute the pseudo-inverse
`\qquad` (or matrices needed to apply the inverse)
`\quad O(m_R^2m_S)` to apply the pseudo-inverse.
Further reading
The theorem and proof for LRA via sampling is an adaptation of Theorem 2.5 ofKannan, Ravindran, and Santosh Vempala.
"Randomized Algorithms in Numerical Linear Algebra." Acta Numerica 26 (2017): 95.
Using a tree to sample (the same tree used in quantum computing for the QRAM) comes from
Tang, Ewin.
"A quantum-inspired classical algorithm for recommendation systems." Proceedings of the 51st annual ACM SIGACT symposium on theory of computing. 2019.
See also the other quantum-inspired papers mentioned.
Leverage-score sampling
More better variance reduction
Want sampler `\mS` so that `\norm{\mS\mA\vx}` is a good estimator of `\norm{\mA\vx}`
We've seen:- Uniform sampling: `p_i\propto\frac{1}{n}` might miss big rows
- Length-squared (row) sampling: `p_i\propto \norm{\mA_{i*}}^2` is better,
but for some `\vx` maybe `\mA_{i*}\vx = 0` even if `\norm{\mA_{i*}}` is large
In either, maybe `\mA_{i*}\vx` is relatively large, and other entries of `\mA\vx` small
`\implies` large variance
We want the terms `(\frac{1}{\sqrt{p_i}}\mA_{i*}\vx)^2` to be "well-behaved"
for all `i` and `\vx`
Bounded sensitivity sampling
`\qquad\qquad` bounded relative contribution
The `i`th row contributes `(\mA_{i*}\vx)^2` to `\norm{\mA\vx}^2 = \sum_i (\mA_{i*}\vx)^2`
- unit `\vy\in\im \mA`
- `\vtau\in\R^n` has `\tau_i \ge y_i^2` for `i\in [n]`
- `\vs` is a sampling vector with distribution `\vp = \vtau/t`, where `t\equiv \sum_i \tau_i\ge\norm{\vy}^2`
Then as expected `\E[(\vs^\top\vy)^2] = \sum_i p_i \left(\frac{y_i}{\sqrt{p_i}}\right)^2 = \norm{\vy}^2`. But also:
- Larger entries of `\vy` are more likely to be picked
- If `i` is picked, the estimate is `\left(\frac{y_i}{\sqrt{p_i}}\right)^2 = \frac{y_i^2}{\tau_i/t} \le t`.
- So the estimate has a uniform upper bound of `t=\sum_i \tau_i`, always.
Extending from a sampling vector to a sampling matrix `\mS\in\R^{m\times n}`,
the estimate is a mean of `m` values, each bounded by `t`.
Using e.g. Bernstein's inequality, such estimates concentrate around their mean.
This can be done by finding `\vtau` with `\tau_i\ge y_i^2` for all unit `\vy\in\im(\mA)`.
Leverage scores
For `i\in[n]` the `i`'th leverage score `\tau_i(L)\equiv\sup_{\vy\in L} y_i^2/\norm{\vy}^2`.
Rows with a high score have more effect, more "leverage", on the least-squares fit.
For `i\in[n]`, the `i`'th leverage score $$\tau_i(\mA) = \sup_{\vx} \frac{(\mA_{i*}\vx)^2 }{ \norm{\mA\vx}^2} = \norm{\mU_{i*}}^2.$$
`\begin{align*} \sup_{\vx} \frac{(\mA_{i*}\vx)^2 }{ \norm{\mA\vx}^2} = \sup_{\vy} \frac{(\mU_{i*}\vy)^2 }{ \norm{\mU\vy}^2 } = \sup_{\vy} \frac{(\mU_{i*}\vy)^2 }{ \norm{\vy}^2 } = \norm{\mU_{i*}}^2. \end{align*}`
`\tau_i(\mA) \in [0,1]`.
Leverage-score sampling: concentration
`\quad\E[\mX] = 0`,
`\quad\norm{\mX}_2 \le \gamma`, and
`\quad \norm{\E[\mX^2]}_2 \le \sigma^2`.
Then for `\eps\gt 0`,
`\qquad \Prob\{\norm{\frac1{m}\sum_k \mX_k}_2 \ge \eps\} \le 2d\exp(-m\eps^2/(\sigma^2 + \gamma\eps/3)).`
Construct a sampling matrix `\mS` using probabilities `p_i = \tau_i(\mA)/r`, so `\mS_{k*}=\ve_I/\sqrt{m p_I}` with `\Prob\{I=i\}=p_i`
There is `m = O(\eps^{-2}r\log(r/\delta))` so that `\mS` is an `\eps`-embedding of `\im(\mA)`, with failure probability `\delta`.
For `k\in[m]`, let `\mX_k = m\mU^\top[\mS_{k*}]^\top\mS_{k*}\mU - \Iden`, so `\frac{1}{m}\sum_k \mX_k = \mU^\top\mS^\top\mS\mU - \Iden`,
and for an `\eps`-embedding, we bound its spectral norm.
We apply matrix Chernoff to
`\mX = \frac{1}{p_I}[\mU_{I*}]^\top\mU_{I*} - \Iden` with `\Prob\{I=i\}=p_i=\tau_i(\mA)/r=\norm{\mU_{i*}}^2/r`.
We have:
- `\E[\mX] = \E_I[\frac{1}{p_I}[\mU_{I*}]^\top\mU_{I*} - \Iden] = \mU^\top\mU - \Iden = 0`.
- `\norm{\mX}_2 \le\max_I\frac{1}{p_I}\norm{[\mU_{I*}]^\top\mU_{I*}}_2 + \norm{\Iden}_2 = \frac{r}{\tau_I}\norm{\mU_{I*}}^2 + 1 = r + 1`.
- `\begin{align*}
\E[\mX^2]
& = \E_I[\frac{1}{p_I^2}[\mU_{I*}]^\top\mU_{I*}[\mU_{I*}]^\top\mU_{I*}]
-2\E_I[\frac{1}{p_I}[\mU_{I*}]^\top\mU_{I*}]
+ \Iden
\\ & = \E_I[\frac{\tau_I}{p_I^2} [\mU_{I*}]^\top\mU_{I*}] - 2\mU^\top\mU + \Iden
= r\Iden - 2\Iden + \Iden
= (r-1)\Iden,
\end{align*}`
so `\norm{\E_I[\mX^\top\mX]}_2 \le r-1`.
We can apply matrix Chernoff with `\gamma = r + 1` and `\sigma^2 = r-1`, obtaining
`\Prob\{\norm{\frac1{m}\sum_k X_k}_2 \ge \eps\} \le 2r\exp(- m\eps^2/((r-1) + (r + 1)\eps/3))`.
For `m = O(\eps^{-2} r\log(r/\delta))`, this is at most `\delta`.
Approximate scores
Sometimes sampling can only be done with probabilities that are only approximations to the leverage scores.Construct a sampling matrix `\mS` using probabilities `p_i \ge \tau_i(\mA)/({\color{red}\alpha} r)`, so `\mS_{k*}=\ve_I/\sqrt{m p_I}` with `\Prob\{I=i\}=p_i`
There is `m = O(\eps^{-2}{\color{red}\alpha} r\log(r/\delta))` so that `\mS` is an `\eps`-embedding of `\im(\mA)`, with failure probability `\delta`.
For `k\in[m]`, let `\mX_k = m\mU^\top[\mS_{k*}]^\top\mS_{k*}\mU - \Iden`, so `\frac{1}{m}\sum_k \mX_k = \mU^\top\mS^\top\mS\mU - \Iden`,
and for an `\eps`-embedding, we bound its spectral norm.
We apply matrix Chernoff to
`\mX = \frac{1}{p_I}[\mU_{I*}]^\top\mU_{I*} - \Iden` with `\Prob\{I=i\}=p_i=\tau_i(\mA)/{\color{red}\alpha} r=\norm{\mU_{i*}}^2/{\color{red}\alpha} r`.
We have:
- `\E[\mX] = \E[\frac{1}{p_I}[\mU_{I*}]^\top\mU_{I*} - \Iden] = \mU^\top\mU - \Iden = 0`.
- `\norm{\mX}_2 \le\frac{1}{p_I}\norm{[\mU_{I*}]^\top\mU_{I*}}_2 + \norm{\Iden}_2 \le \frac{{\color{red}\alpha} r}{\tau_I}\norm{\mU_{I*}}^2 + 1 = {\color{red}\alpha} r + 1`.
- `\begin{align*}
\E[\mX^2]
& = \E[\frac{1}{p_I^2}[\mU_{I*}]^\top\mU_{I*}[\mU_{I*}]^\top\mU_{I*}]
-2\E[\frac{1}{p_I}[\mU_{I*}]^\top\mU_{I*}]
+ \Iden
\\ & = \E[\frac{\tau_I}{p_I^2} [\mU_{I*}]^\top\mU_{I*}] - 2\mU^\top\mU + \Iden
\le {\color{red}\alpha} r\Iden - 2\Iden + \Iden
= ({\color{red}\alpha} r-1)\Iden,
\end{align*}`
so `\norm{\E[\mX^\top\mX]}_2 \le {\color{red}\alpha} r-1`.
We can apply matrix Chernoff with `\gamma = {\color{red}\alpha} r + 1` and `\sigma^2 = {\color{red}\alpha} r-1`, obtaining
`\Prob\{\norm{\frac1{m}\sum_k X_k}_2 \ge \eps\} \le 2r\exp(- m\eps^2/(({\color{red}\alpha} r-1) + ({\color{red}\alpha} r + 1)\eps/3))`.
For `m = O(\eps^{-2} {\color{red}\alpha} r\log(r/\delta))`, this is at most `\delta`.
Friends and relations
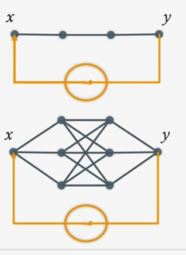
- If `\mU` has orthonormal columns,
its rows are in isotropic position - e.g., `\mA\mR^{-1}`, where `\mA=\mQ\mR`
- Leverage score sampling == length-squared sampling
for matrix with rows in isotropic position. - As applied to volume of convex bodies,
coresets for Minimum Enclosing Ellipsoids;
coresets==small subsets with about the same MEE
Also:
- Diagonal of hat matrix (influence matrix, projection matrix)
- Spectral sparsification & effective resistance
- Effective resistances == leverage scores of vertex-edge incidence matrix
- Regression, and extension to `\ell_p`
- Low-rank approximation: robust, and CUR
- Sensitivity, more generally
- `\equiv` max relative cost of loss `i`, over all `\vx`
- High sensitivity == one definition of "outlier"
Computing leverage scores
Roughly: use sketch to get `\approx`orth. basis, use its row norms(Same pre-conditioner scheme as for regression)
Given
- Input matrix `\mA `
- subspace `\eps`-embedding matrix `\mS\in\R^{m\times n}` for `\mA `
- embedding (JL) matrix `\mathbf{\Pi}\in\R^{d\times m'}`,
so `\norm{\vx^\top\mathbf{\Pi}}=(1\pm\eps)\norm{\vx }` for `n` vectors `\vx `- `m'=O(\eps^{-2}\log n)`
The algorithm:
| `\mW = \mS *\mA `; | // compute sketch |
| `[\mQ,\mR ] = \mathtt{qr}(\mW )`; | // compute change-of-basis for `\mS\mA ` |
| `\mZ = \mA *(\mR^{-1}*\mathbf{\Pi})`; | // compute sketch of `\mA\mR^{-1}` |
| return `\mathtt{dot}(\mZ,\mZ,2)`; | // return vector of squared row norms |
Computing leverage scores: correctness
Let `\mU` be an orthonormal basis for `\im(\mA)`
`\mA\mR^{-1}` is "morally" like `\mU`,
pick `\mT` to translate, so that `\mA\mR^{-1}\mT = \mU`
Computing leverage scores: running time
| `\mW = \mS *\mA `; | // `O(\nnz{\mA }s)` when `\mS ` is a sparse embedding, param `s` |
| `[\mQ,\mR ] = \mathtt{qr}(\mW )`; | // `O(d^2m)` |
| `\mZ = \mA *(\mR^{-1}*\mathbf{\Pi})`; | // `O(d^2m') +O(\nnz{\mA }m')` |
| return `\mathtt{dot}(\mZ,\mZ,2)`; | // `O(nm')` |
Grand total, for `s=O(1/\eps)`, `m =O(d^{1+\gamma}/\eps^2)` [NN] $$\begin{align*} O(\nnz{\mA }(m'+s) & + O(d^2(m+m') \\ & = O(\nnz{\mA}\eps^{-2}\log n) + O(d^2\eps^{-2}(\log(n) + d^{1+\gamma}))\end{align*}$$
Or, use `s=O(\eps^{-1}\log d)`, `m=O(\eps^{-2}d\log d)` [Coh]
Leverage scores, finis
Constant `\eps` is good enough for many purposes, such as leverage score sampling
For sampling, sometimes can make `m'=O(1/\eps^2)`
very crude estimates, but still good enough
(Maybe use `s=O(1/\eps)` to remove all logs in leading term)
Further Reading
The algorithm is basically due to:
Petros Drineas, Malik Magdon-Ismail, Michael W. Mahoney, David P. Woodruff. Fast approximation of matrix coherence and statistical leverage.
Subsampled Randomized Hadamard Transform
SRHT: the Subsampled Randomized Hadamard Transform
- In the original JL:
- Pick random orthogonal matrix `\mQ `
- Sketching matrix `\mS\equiv` the first `m` rows of `\mQ `
- `O(mnd)` time to compute `\mS\mA `
- A faster scheme: pick a random orthogonal matrix, but:
- Use fewer random bits
- Make it faster to apply
This is "Fast JL", here we discuss a variant
- `\mD\in\R^{n\times n}` is diagonal with i.i.d. `\pm 1` on diagonal
- `\mH\in\R^{n\times n}` is a Hadamard matrix (orthogonal, fast multiply)
- `\mP\in\R^{m\times n}` uniformly samples rows of `\mH\mD`
`\qquad\qquad\small{ \underbrace{\left[\begin{matrix} 0 & 0 & 0 & \cdots & 1 \\ 1 & 0 & 0 & \cdots & 0 \\ 0 & 0 & 1 & \cdots & 0 \end{matrix}\right]}_\mP \underbrace{\left[\begin{matrix} 1 & 1 & 1 &\cdots & 1 \\ 1 & -1 & 1 &\cdots & -1\\ 1 & 1 & -1 &\cdots & -1\\ \vdots & \vdots & \vdots & \cdots & \vdots \\ 1 & -1 & -1 &\cdots&1 \\ \end{matrix}\right]}_{\sqrt{n}\mH} \underbrace{\left[\begin{matrix} \pm 1 & 0 & 0 &\cdots & 0 \\ 0 & \pm 1 & 0 &\cdots & 0\\ 0 & 0 & \pm 1 &\cdots & 0\\ \vdots & \vdots & \vdots & \ddots & \vdots \\ 0 & 0 & 0 &\cdots& \pm 1 \\ \end{matrix}\right]}_\mD } `
Hadamard: definition
Hadamard matrices have a recursive construction
Let `\mH_{i+1}\equiv\frac{1}{\sqrt{2}}\left[\begin{matrix}\mH_i & \mH_i\\\mH_i & -\mH_i\end{matrix}\right]` for `i\ge 0`
In general, `\mH_k` is `2^k\times 2^k` matrix of `\pm 1`, scaled by `1/2^{k/2}`
Hadamard: properties
where `\vx ',\vx ''\in\R^{2^{k-1}}`.
Then `\mH_{i+1}\vx =\left[\begin{smallmatrix} \mH_i \vx' +\mH_i\vx'' \\ \mH_i\vx' - \mH_i\vx''\end{smallmatrix}\right]`,
so `\mH_{i+1}\vx` found in linear time from `\mH_i\vx'` and `\mH_i\vx''`
Analysis of Fast Hadamard
Via the "flatness" of the leverage scores:There is $$m = O(d\eps^{-2}\log(d/\delta)\left(1+\sqrt{8\log(n/\delta)/d}\right)^2)$$ so that with failure probability `\delta`, `\mP\mH\mD ` is an `\eps`-embedding of `\im(\mA )`.
`\frac{1/n}{\tau_i/d} \ge \frac{1}{(1+\sqrt{8\log(n/\delta)/d})^2}`
Flatness of leverage scores of `\mH\mD\mA`
so `f(\vx)-f(\vy) \le L\norm{\vx-\vy}`.
Then for `t\ge 0` and `\vr` a sign (Rademacher) vector, so `r_i=\pm 1` with equal probability, $$\Prob\{f(\vr) - \E[f(\vr)] \ge Lt\} \le \exp(-t^2/8).$$
where `\mH,\mD,\mA` are as above.
Then `\E[f(\mD )]\le\sqrt{d/n}`.
We have $$ \sum_i f_i(\mD)^2 = \sum_i \tau_i(\mH\mD\mA) = \rank(\mH\mD\mA) = d. $$ The random variables `\norm{\mH_{i*}\mD\mA }` have the same distribution, for all `i`,
so for any `i`, `\E[f_i(\mD)^2] = \frac1n\sum_{i'} \E[f_{i'}(\mD)^2] = \frac{d}n`,
and `\E[f(\mD )] \le \E[f(\mD)^2]^{1/2} \le \sqrt{d/n}`, using Jensen's inequality.
Since `\norm{\cdot}` is convex, and `\mH_{i*}\mD\mA` is a linear function of `\mD`, `f(\mD )\equiv\norm{\mH_{i*}\mD\mA }` is convex.
Lipschitz:
Let `\vm = [\mH_{i*}]^\top`. Then
`(\vm^\top\mD)_j = m_j d_{jj}`, or equivalently `d_j m_{jj}`, where `\vd` has `\mD=\diag(\vd)` and `\mM = \diag(\vm)`. That is,
`\vm^\top\mD = \vd^\top\mM`, and we could write `f(\mD)= \hat f(\vd) = \norm{\vd^\top\mM\mA}`.
We have
`\begin{align*} |\hat f(\vd) - \hat f(\vd')| & = |\,\norm{\vd^\top\mM\mA} - \norm{(\vd')^\top\mM\mA}\,| \\ & \le \norm{(\vd - \vd')^\top\mM\mA}& \text{ triangle inequality} \\ & \le \norm{\vd - \vd'}\,\norm{\mM}_2\norm{\mA}_2&\text{ Def. of spectral norm} \\ & = \frac{1}{\sqrt{n}}\norm{\vd - \vd'}\quad\implies \frac{1}{\sqrt{n}}\text{-Lipschitz} \end{align*}`
`\Prob\{\sqrt{\tau_i}\ge \sqrt{d/n} + t/\sqrt{n} \} \le \exp(-t^2/8) = \delta/n`
for `t=\sqrt{8\log(n/\delta)}`; this implies the result,
taking a union bound over all `i\in[n]`.
Approximate Matrix Multiplication with SRHT
There is `m=O(\eps^{-2}(\log(n/\delta)^2)` so that an SRHT `\mS=\mP\mH\mD\in\R^{m\times n}` has $$\norm{\mB\mS^\top\mS\mA - \mB\mA}_F \le \eps\norm{\mA}_F\norm{\mB}_F$$ with failure probability at most `\delta`.
Using SRHT to build a better `\mS `
- Sparse embeddings take `O(\nnz{\mA })` to apply, but `m=O(d^2/\eps^2)`
- Or `O(\nnz{\mA }/\eps)` to apply, with `m=O(d^{1+\gamma}/\eps^2)`.
- For sparse embeddings with `s\gt 1` nonzeros per column
- Or: `O(\nnz{\mA }) +\tO(d^3/\eps^2)` to map to `m= \tO(d/\eps^2)`
- First apply a sparse embedding, then SHRT
- Subspace embeddings compose
- Matrix product approximators compose
Further Reading
The analysis outline is slightly simplified from:
Joel Tropp. Improved analysis of the subsampled randomized Hadamard transform.
Multiple-response
least-squares regression,
low-rank approximation
Fitting data: low-rank approximation
- Fit: a `k`-dimensional subspace `L^*` minimizing $$\cost(\mA,L) \equiv \sum_{i\in [n]} \dist(\mA_{i*},L)^2$$ among all `k`-dimensional subspaces
- That is, $$\min_{\substack{\mY\in\R^{n\times k}\\ \mX\in\R^{k\times d}}} \norm{\mY\mX - \mA}_F^2.$$
- `\OPT` from Singular Value Decomposition (SVD) (PCA, LSI, EigenX,...)
- For fixed `\mY`, least-squares for each column of `\mX`
- For fixed `\mX`, least-squares for each row of `\mY`
- Length-squared sampling gives a CUR decomposition.
- We seek relative error approximation:
given `\eps\gt 0`, find `\tmY,\tmX` with $$\norm{\tmY\tmX - \mA}_F^2 \le (1+\eps)\OPT$$
Multiple-response regression
- `\mA\in\R^{n\times d}`
- `\mB\in\R^{n\times d'}`
The multiple-response, or generalized, regression problem is to find $$\argmin_{\mX\in\R^{d\times d'}}\norm{\mA\mX -\mB}_F$$
Since $$\norm{\mA\mX -\mB}_F^2 = \sum_{j\in[d']}\norm{\mA\mX_{*j} - \mB_{*j}}^2,$$ no harder than `d'` independent least-squares problems.
But: using the same sketch for `d'` subspace embeddings doesn't (provably) work if failure probability is too large.
- Countsketch: constant failure probability per right-hand-side ☹️
- Leverage-score sampling
- Exponentially small failure probability 😀
- Not oblivious ☹️
to do low-rank approximation.
Good regression sketches `\implies` weak coresets
Then `\mY^* = \mA(\mX^*)^+`, and `\mX^*=(\mY^*)^+\mA`
So `\mY^*= \mA\mW`, `\mX^*= \mH\mA` for some matrices `\mW` and `\mH^\top` with `k` columns.
`\quad\tmY \equiv \argmin_{\mY\in\R^{n\times k}} \norm{(\mY \mX^* - \mA)\mR}_F^2`
has
`\quad\norm{\tmY \mX^* - \mA}_F^2 \le (1+\eps)\norm{\mY^*\mX^*-\mA}_F^2`.
Then WLOG, `\tmY=\mA\mR\tmW` for some `\tmW` with `k` columns,
and
`\quad\norm{\mA\mR\tmW\mX^* - \mA}_F^2 \le (1+\eps)\norm{\mY^*\mX^*-\mA}_F^2`.
so `\tmW=(\mX^*\mR)^+` satisfies the conditions.
The columns of `\mA\mR` contain a left factor of a low-rank approximation: it is a weak coreset
Similar observations, applying sketching matrix `\mS` to `\min_{\mX\in\R^{k\times d}} \norm{\mA\mR\tmW \mX - \mA}_F^2`, yield the following.
Low-rank approximation: reduction to `\mA\mR\mZ\mS\mA`
`\mR` giving `\eps`-approximate solution `\mA\mR\tmW` to `\min_{\mY\in\R^{n\times k}} \norm{\mY \mX^* - \mA}_F^2`,
`\mS` giving `\eps`-approximate solution `\tmH \mS\mA` to `\min_{\mX\in\R^{k\times d}} \norm{\mA\mR\tmW \mX - \mA}_F^2`.
Then $$\tmW, \tmH \equiv \argmin_{\substack{\mW\in\R^{m_R\times k}\\\mH\in\R^{k\times m_S}}} \norm{\mA\mR\mW\mH\mS\mA - \mA}_F^2$$ gives rank-`k` matrix `\mA\mR\tmW\tmH \mS\mA` with `\norm{\mA\mR\tmW\tmH \mS\mA - \mA}_F \le (1+O(\eps))\min_{\rank(\mB)=k}\norm{\mB - \mA}_F`.
$$\begin{align*} \min_{\substack{\mY\in\R^{n\times k}\\ \mX\in\R^{k\times d}}} \norm{\mY & \mX - \,\, \!\!\mA }_F \\[-10em] & \Bigg\downarrow & \\[-9em] \min_{\rank(\mZ)=k} \norm{\mA\mR & \mZ\mS\mA - \mA}_F \end{align*}$$

- Finding oblivious sketching distributions "good for regression"
- Solving the resulting problem
Least-squares regression, again: weaker conditions
Before:
`\mS ` a subspace `\eps`-embedding for `[\mA\ \vb]\implies`
`\argmin_{\vx\in\R^d}\norm{\mS (\mA\vx -\vb)}` `\eps`-approx for `\min_{\vx\in\R^d}\norm{\mA\vx
-\vb}`
- `\mA\in\R^{n\times d}` with `\rank(\mA )=r`, `\vb\in\R^n`
- `\mS ` with `\norm{\mW\mS^\top\mS\mW' - \mW\mW'}_F \le \frac23\sqrt{\eps/r}\norm{\mW}_F\norm{\mW'}_F` for fixed unknown `\mW ,\mW '`
- `\mS ` a subspace `(1/9)`-embedding for `\mA `
Then for $$ \begin{align*} \tvx & \equiv\argmin_{\vx\in\R^d}\norm{\mS (\mA\vx -\vb)} \\\vx_* & \equiv\argmin_{\vx\in\R^d}\norm{\mA\vx -\vb}, \end{align*} $$ we have $$\norm{\mA\tvx -\vb}\le (1+\eps)\Delta_*,\text{ where }\Delta_*\equiv\norm{\mA\vx_*-\vb}$$
`\qquad \norme{\norm{\mS^\top\mS-\Iden}_{\{\vy\}}}_{2} \le K\min\{\sqrt{\eps/r}, 1/r\}`
then the above conditions hold. A countsketch embedding to `O(r/\eps + r^2)` dimensions suffices.
Proof, least squares from AMM + const-embedding, 1/2
- We can assume WLOG `\mA ` has orthonormal columns
- `\mS ` is a `(1/9)`-embedding $$\implies\norm{\mA^\top\mS^\top\mS\mA -\Iden}_2\le 1/3 \implies \sigma_\min(\mA^\top\mS^\top\mS\mA) \ge 2/3$$
- The normal equations: $$\mA^\top (\mA\vx^* -\vb) = 0 = \mA^\top\mS^\top\mS (\mA\tvx -\vb)$$
- Using the first normal eq. and by Pythagoras,
$$\begin{align*}
\norm{\mA\tvx-\vb}^2 & = \norm{\mA\tvx -\mA\vx^*}^2 +\norm{\mA\vx^*-\vb}^2\\ & = \norm{\tvx
-\vx^*}^2 +\Delta_*^2
\end{align*}$$
- By (1), `\norm{\mA\vy }= \norm{\vy }`
So it is enough show that $$\norm{\tvx -\vx^*}\le\sqrt{\eps}\Delta_*.$$ (Note: this bound is for `\tvx,\vx^*` for `\mA` assumed orthonormal, that is, where an orthonormal basis is used for the analysis.)
Proof, least squares from AMM + const-embedding, 2/2
$$\begin{alignat*}{2} (2/3) & \norm{\tvx -\vx^*} & & \\ & \le \norm{\mA^\top \mS^\top\mS\mA (\tvx-\vx_*)} & & \,(\text{since }\sigma_\min(\mA^\top\mS^\top\mS\mA )\ge 2/3 ) \\ & = \norm{\mA^\top\mS^\top\mS (\mA\tvx -\mA\vx_*) \\ & \qquad\qquad -\mA^\top\mS^\top\mS (\mA\tvx -\vb) } & & \,(\text{normal eq. for sketched problem} ) \\ & = \norm{\mA^\top\mS^\top\mS (\vb -\mA\vx_*) } & & \\ & \le (2/3)\sqrt{\eps/r}\norm{\mA }_F\norm{\vb-\mA\vx^*} & & \,(\text{normal eq. for given problem, AMM bound} ) \\ & = (2/3)\sqrt{\eps}\Delta_*, & & \,(\rank(\mA )=r,\mA^\top\mA = \Iden ) \end{alignat*}$$
So $$\norm{\tvx -\vx^*}\le \sqrt{\eps}\Delta_*,$$ as claimed.
Multiple-response regression
Nearly the same proof as for 1-response regression shows:- `\mA\in\R^{n\times d}` with `\rank(\mA )=r`, `\mB\in\R^{n\times d'}`
- `\mS ` with `\norm{\mW\mS^\top\mS\mW' - \mW\mW'}_F \le \frac23\sqrt{\eps/r}\norm{\mW}_F\norm{\mW'}_F` for fixed unknown `\mW ,\mW '`
- `\mS ` a subspace `(1/9)`-embedding for `\mA `
Then for $$ \begin{align*} \tmX & \equiv\argmin_{\mX\in\R^{d\times d'}}\norm{\mS (\mA\mX -\mB)}_F \\\mX_* & \equiv\argmin_{\mX\in\R^{d\times d'}}\norm{\mA\mX - \mB}_F, \end{align*} $$ we have $$\norm{\mA\tmX-\mB}_F\le (1+\eps)\Delta_*,\text{ where }\Delta_*\equiv\norm{\mA\mX _*-\mB}_F$$
- Same conditions on sketch as for 1-response
- `\norm{\text{vector}}\rightarrow\norm{\text{matrix}}_F`
- Pythagoras `\rightarrow` Matrix Pythagoras:
if matrices `\mA,\mB` have `\trace\mA^\top\mB=0`, then `\norm{\mA+\mB}_F^2 = \norm{\mA}_F^2 + \norm{\mB}_F^2`
A sparse embedding to `O(r/\eps + r^2)` dimensions suffices.
Low-rank approximation
Putting this construction for multiple-response regression withthe reduction of low-rank approximation,
there is sketching distribution `\mR\in\R^{d\times m_R}`
and sketching distribution `\mS\in\R^{m_S\times n}`, with `m_R,m_S=O(k/\eps + k^2)`, so that with constant failure probability `\begin{equation}\label{eq LRA}\tmZ \equiv \argmin_{\mZ:\rank(\mZ)=k} \norm{\mA\mR\mZ\mS\mA - \mA}_F^2 \end{equation}` gives rank-`k` matrix `\mA\mR\tmZ \mS\mA` with
$$\norm{\mA\mR\tmZ \mS\mA - \mA}_F \le (1+O(\eps))\min_{\rank(\mB)=k}\norm{\mB - \mA}_F.$$
and then the reduction of the latter to the single vector case,
and then conditions on sparse embeddings for the single vector case.
Note that in the reduction from LRA,
`\rank(\mX^*)=\rank(\mA\mR\tmW)=k`,
so `m_R, m_S=O(k/\eps + k^2)` suffice.
It remains to solve `\eqref{eq LRA}`.
We can further reduce the problem size using...
more sketching: affine embeddings.
Affine embeddings
Affine embeddings are like subspace embeddings, but "translated by `\mB `"
it applies in `\min_{\mZ:\rank(\mZ)=k}\norm{\mA\mR\mZ\mS\mA - \mA}_F^2` to `\mX` of the form `\mZ\mS\mA`.
Affine embeddings need a bit more from sketching matrices:
- `\mA\in\R^{n\times d}` with `\rank(\mA )=r`, `\mB\in\R^{n\times d'}`
- `\mT` with `\norm{\mW\mT^\top\mT\mW' - \mW\mW'}_F \le K_1\eps/\sqrt{r}\norm{\mW}_F\norm{\mW'}_F`
for fixed unknown `\mW ,\mW '`, constant `K_1` - `\mT ` a subspace `K_2\eps`-embedding for `\mA `, constant `K_2`
Then
`\mT ` is an affine `\eps`-embedding for `\mA ,\mB `, when `K_1` and `K_2` are small enough.
Low-rank approximation: the final sketching reduction
Now we pick affine embedding sketching matrices `\mS_\ell\in\R^{m_\ell\times n}` and `\mS_r\in\R^{d\times m_r}`, so our reduction is:$$\begin{align*} \min \norm{\mA - \,\, & \!\!\mY \mX }_F \\[-10em] & \Bigg\downarrow & \\[-10em] \min_{\rank(\mZ)=k} \norm{\mA - \mA\mR & \mZ \mS\mA}_F \\[-10em] & \Bigg\downarrow & \\[-40em] \min_{\rank(\mZ)=k} \norm{ \mS_\ell (\mA - \mA\mR & \mZ \mS\mA) \mS_r}_F \end{align*}$$

Low-rank approximation: overall
Assuming the reduced problem can be solved in `\poly(k/\eps)` time, we have:There is a construction that with constant failure probability finds `\mA\mR\in\R^{n\times m_R}, \mS\mA\in\R^{m_S\times d}`, `\tmZ\in\R^{m_R\times m_S}` of rank `k`, where `m_R,m_S=O(k/\eps + k^2)`
such that `\norm{\mA\mR\tmZ\mS\mA - \mA}_F\le (1+\eps)\min_{\mB:\rank(\mB)=k} \norm{\mB - \mA}_F`,
taking time `\tO(\nnz{\mA}) + O(n+d)\poly(k/\eps) + \poly(k/\eps).`
- `\tO(\nnz{\mA})` for sketching
- `\poly(k/\eps)` to solve small-matrix problem (a low-rank approx problem)
- `O(n+d)\poly(k/\eps)` to compute `\mA\mR\tmY` and `\tmX\mS\mA`,
where `\tmZ=\tmY\tmX`, and `\tmY` and `\tmX^\top` have `k` columns
The Generalized Low-Rank Approximation problem is $$\min_{\textrm{rank}(\mX)= k} \|\mA - \mB \mX \mC \|^2_F,$$ and one solution is $$\mX = \mB^+[\mP_\mB \mA \mP_{\mC^\top}]_k \mC^+,$$ where `\mP_{\mB},\mP_{\mC^\top}` are the projection matrices onto `\im(\mB)` and `\im(\mC^\top)` respectively. Here `[\mW]_k` denotes the best rank-`k` approximation to `\mW`.
Low-rank approximation: regularization
Regularization $$\norm{\mY\mX-\mA}_F^2 \color{red}{+ \lambda(\norm{\mY}_F^2 + \norm{\mX}_F^2)}$$ just adds sketched regularizers.
$$\tmW, \tmZ \equiv \argmin_{\mW,\mZ} \norm{\hmS \mA\mR\mW\mZ\mS\mA \hmR - \hmS A \hmR}_F^2 \color{red}{+ \lambda(\norm{\hmS\mA\mR\mW}_F^2 + \norm{\mZ\mS\mA\hmR}_F^2)}$$ gives rank-`k` matrix `\mA\mR\tmW\tmZ \mS\mA` with cost `(1+O(\eps))\OPT`
Using orthogonal invariance of `\norm{\cdot}_F`
reducible to regularized low-rank approximation.
- `F(\cdot,\cdot)` is subadditive in each argument
- `F(\mY,\mX) = F(\mU\mY, \mX\mV)` for all orthogonal `\mU,\mV`, and
- `F(\mY,\mX) = F\left(\left[\begin{smallmatrix}\mY & \mZero \\ \mZero & \mZero \end{smallmatrix}\right], \left[\begin{smallmatrix} \mX & \mZero \\ \mZero & \mZero \end{smallmatrix}\right]\right)`
So for example `F(\mY,\mX) = \min\{\norm{\mY^\top}_{2,1} + \norm{\mX}_{2,1}, \norm{\mY\mX}_*^{1/2} \}.`
(Where `\norm{\mE}_{2,1} \equiv \sum_i \norm{\mE_{i*}}_2`)
Ridge regression
Work for some regularized problems can be provably less
Ridge regression: $$\min_{\vx\in\R^d} \norm{\mA\vx - \vb}^2 + \lambda\norm{\vx}^2,$$ Sketched version: $$\min_{\vx\in\R^d} \norm{\mS(\mA\vx - \vb)}^2 + \lambda\norm{\vx}^2.$$
When `\lambda` is very large, `\lambda\norm{\vx}^2` dominates, and
`\norm{\mS(\mA\vx - \vb)}^2 = (1+\eps) \norm{\mA\vx - \vb}^2` can have larger `\eps`.
So ridge regression should get easier as `\lambda` increases.
How much easier?
The statistical dimension of ridge regression
Note that
`\sd_\lambda(\mA)\le \rank(A)\le \min\{n,d\}`, and
`\sd_\lambda(\mA)` is decreasing in `\lambda`.
Relates to sample complexity, ridge leverage scores
Smaller embeddings for ridge regression
`\tO(\eps^{-1}\sd_\lambda(\mA))` rows, in
`O(\nnz{\mA}) + \tO(d\sd_\lambda(\mA)(\eps^{-1} + \sd_\lambda(\mA)))` time.
The resulting problem yields a `(1+\eps)`-approximation.
- This are also similar results with `\sd` for sampling
- Similarly for low-rank approximation; some `k\rightarrow O(\eps^{-1}\sd_\lambda(\mY_*))`
- There is another reduction that reduces `d` to $$\poly(\sd_\lambda(\mA) \eps^{-1} (\sigma_1(\mA)^2/\lambda))$$
- Contrast with "truncated optimization `\equiv` regularization" [MO11]
Low-rank approximation: robust
Suppose $$\mY^*, \mX^* \equiv \argmin_{\substack{\mY\in\R^{n\times k}\\{\mX\in\R^{k\times d}}}} \norm{\mY \mX - \mA}_{2,1}^2$$- Where `\norm{\mE}_{2,1} \equiv \sum_i \norm{\mE_{i*}}_2`; more generally `\norm{\mE}_M \equiv \sum_i M(\norm{\mE_{i*}}_2)` for `M(\cdot)`
As before, `\mY^*= \mA\mW`, `\mX^* = \mZ\mA` for some `\mW,\mZ`
For `\mX^*`, follows as before; for `\mY^*`, because `\mY^* = \mA(\mX^*)^+`
Can sketch on the right, since
`\norm{\mE_{i*}\mR}_2 = (1\pm\eps)\norm{\mE_{i*}}_2`,
reduce to `\min_{\mW\in\R^{m\times k}, \mX\in\R^{k\times d}} \norm{\mA\mR\mW\mX -
\mA}_M`
But: need new proof that `\mR` gives good approximate solution
Also: need subspace embedding `\mS` on the left, so that `\norm{\mS\mA\mR\mW\mX}_M \approx \norm{\mA\mR\mW\mX}_M`.
Construct `\mS` to sample rows of `\mA\mR`,use `\eps`-net arguments in `\norm{\cdot}_M` space
- Leverage score sampling of `\mA\mR` `\rightarrow` constant factor solution `\rightarrow` residual sampling `\rightarrow` `(1+\eps)` solution
Oblivious sketches: Sub-Gaussian Matrices
SubGaussian matrices
We've looked at sketching matrices
`\mS\in\R^{m\times n}` with `\E[s_{ij}]=0` and `\Var[s_{ij}]=1/m`,
and shown that when `s_{ij}` is Gaussian,
`\mS` is an `\eps`-embedding with high probability.
Here we consider sketching vectors and matrices with random entries satisfying the sub-Gaussian condition (defined shortly).
A sub-Gaussian sketching vector or matrix has independent sub-Gaussian entries
As discussed next, for sub-Gaussian sketching vector `\vs`, sub-Gaussian sketching matrix `\mS`, and vector `\vy`:
- `\vs^\top\vy `, a weighted sum of sub-Gaussians, is also sub-Gaussian
- `(\vs^\top\vy )^2` is a sub-exponential random variable
- `\norm{\mS\vy }^2` is :
- Also sub-exponential
- Concentrated
Sub-Gaussians as generalizations
Gaussian random variables have many interesting and useful
properties, in particular, small "tails".
Sub-Gaussians are random variables with tails as small as Gaussians.
A random variable with a sub-Gaussian distribution,
denoted `X\sim\subg(\sigma_X^2)`, has
a parameter `\sigma_X`, the variance proxy.
Below, relations for
Gaussians: `X\sim\cN(0,\sigma^2)`,
and independent `X_i\sim\cN(0,\sigma^2)`, and for
Sub-Gaussians: centered `X\sim\subg(\sigma_X^2)`,
and centered independent `X_i\sim\subg(\sigma_X^2)`
("Centered" means `\E[X]=0`)
Cumulant generating functions
The cumulant generating function of real random variable X is
`\cgf_X (t) = \log\E[\exp(tX)]`, for `t\in\R`
It holds that
`\cgf_X(t) = \E[X]t +\frac12\Var[X]t^2 +\sum_{i>2}\frac1{i!}\kappa_i t^i\ldots`
where for `i\ge 1`, `\kappa_i` is the `i`th cumulant
- (Gaussian) If `X\sim N(0,1)`, then `\cgf_X(t) = \frac12t^2`
- (Sign) If `X= \pm 1` with equal probability, `\cgf_X(t) = \log((\exp(t) +\exp(-t))/2) = \log\cosh(t)`
Sub-Gaussians
`X` sub-Gaussian`\iff` there is a variance proxy `\sigma_X^2` with `\cgf_{X-\E[X]}(t)\le\sigma_X^2 t^2/2` for all `t`
- (Gaussian) If `X\sim N(0,\sigma^2)` , `\sigma_X^2= \sigma^2`
- (Sign) If `X= \pm 1` with equal prob., `\frac{e^t + e^{-t}}{2}\le e^{t^2/2}\implies \cgf_X(t) = \log\cosh(t)\le t^2/2`, so `\sigma_X^2=1`
- (Bounded) If `|X|\le M` for some `M`, then `\cgf_{X-\E[X]} (t)\le M^2t^2/2`, so `\sigma_X^2\le M^2`
then `\cgf_{\vs^\top\vy }(t) = \sum_{i\in [n]}\cgf_{s_i y_i}(t)\le\sum_{i\in [n]}y_i^2\sigma^2 t^2/2\le\sigma^2\norm{\vy }^2t^2/2`
That is, `\vs^\top\vy ` is sub-Gaussian with `\sigma_{\vs^\top\vy}^2 \le \sigma^2\norm{\vy }^2`
(Recall that `\Var(\vs^\top\vy) = \sigma^2\norm{\vy}^2` under analogous conditions.)
Concentration for sketching vectors
and for any value `t`, $$\log \Prob\{X\ge\alpha\} \le -t\alpha + \log \E[\exp(tX)].$$
Letting `Y= \exp(tX)` and `C= \exp(t\alpha)` for `\alpha,t\ge 0`, with `X` centered, `\Prob\{X\ge\alpha\} = \Prob\{\exp(tX)\ge\exp(t\alpha)\}\le\E[\exp(tX)]\exp(-t\alpha)`
`\begin{align*} \log\Prob\{X\ge\alpha\} & \le\inf_{t\ge 0} -t\alpha +\cgf_X(t) \\ & = - \sup_{t\ge 0} t\alpha -\cgf_X(t) \le -\alpha^2/2\sigma^2_X. \end{align*}`
Putting this together with the CGF of a linear combination, a "Hoeffding-like":
Concentration for sketching matrices, 1/4
But:
- We want to have an estimate closer to `\norm{\vy }`
- We need even yet more concentration
The summands in `\norm{\mS\vy }^2 = \sum_{j\in[m]} (\mS_{j*}\vy )^2` are sub-exponential:
`X^2` is sub-exponential `\iff` `X` is sub-GaussianSo, the tail of `Y=X^2` decays "only" exponentially:
`\log\Prob\{Y\ge\beta\}\le -\beta/2\sigma^2_X`
Concentration for sketching matrices, 2/4
For small `t`, the `\cgf` of a centered sub-exponential looks like that of a centered sub-Gaussian:Concentration for sketching matrices, 3/4
A "Bernstein-like" tail estimate for sums of sub-exponentials:
`\begin{align*} \log\Prob\{Z-\E[Z]\ge\alpha\} & \le\inf_{t\in [0,K_2m/\sigma^2] } -t\alpha + K_1 t^2\sigma^4/m, \\ & = -\min\{m\alpha^2/4K_1\sigma^4, m\alpha K_2/2\sigma^2\} \end{align*}`
Now let `\alpha= \eps\E[Z] = \eps`. Bounding also for `-Z`, and a union bound, gives the result.
Concentration for sketching matrices, 4/4
Translated to sketching matrices,
That is, independent sub-Gaussian entries yield sketching matrices so that with very high probability, the norm of a single vector is preserved.
Distances
With the concentration results, the conclusions for sketching distances and subspaces follow, as for Gaussians.
For distances among points in `\cP\subset\R^n`, we can apply the concentration results to all vectors in `\cP-\cP=\{\vx-\vy\mid \vx, \vy\in\cP\}`
We have:
- i.i.d. sub-Gaussian entries
- `\E[\norm{\mS\vy }^2] = \norm{\vy}^2` for fixed `\vy\in\R^n`
- `\sigma_{\mS_{ij}}^2\le C/m` for a constant `C`.
For given `\cP\subset \R^n`, there is a constant `K` and `m\le 2K\eps^{-2}\log(2|\cP|)` such that `\norm{\symd{\mS}}_{\cP-\cP} \le \eps` with probability at least `1/2`.
Subspace Embedding
- i.i.d. sub-Gaussian entries
- `\E[\norm{\mS\vy }^2] = \norm{\vy}^2` for fixed `\vy\in\R^n`
- `\sigma_{\mS_{ij}}^2\le C` for a constant `C/m`.
For `\mA\in\R^{n\times d}`, there is `m=O(\eps^{-2}d\log(1/\delta))` so that with failure probability at most `\delta`,
`\mS ` is an `\eps`-embedding for `\im(\mA )`.
Further reading
The discussion of sub-Gaussians and sub-exponentials is cribbed from:
Introduction to the non-asymptotic analysis of random matrices, Roman Vershynin.
Lecture notes on metric embeddings, Jiří Matoušek.